
Google has been busily digitizing the world’s books since 2004. As of December 2010, some 15 million books have been digitized. A couple of months ago, Google Labs announced a new tool called Ngram Viewer that allows the user to analyze and graph word usage over time from a 500-billion-word subset of those 15 million books. Google has divided the 500-billion-word subset into a number of “corpora,” which allow you track usage of words and phrases in English, American English, British English, and a number of foreign languages including Spanish, French, and German. “English Fiction” is a particularly intriguing corpus. The most accurate data are for English-language materials published between 1800 and 2000.
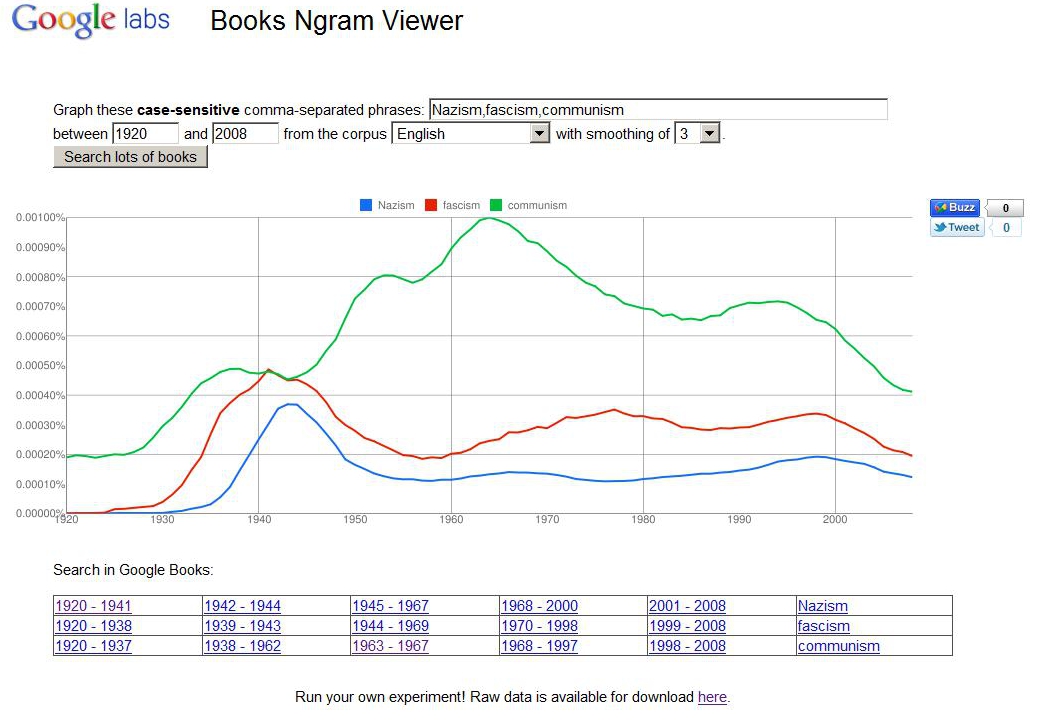
Ngram Viewer makes it possible to track the early appearances of a word or phrase (like “laptop”) in published books, but it’s even more interesting to compare the ascending and descending usage of two or more words or phrases (like “laptop” and “mainframe”) on the same graph. The graph below compares the usage of the words “Nazism,” “fascism,” and “communism” in English-language works published between 1920 and 2008. Not unexpectedly, usage of “Nazism” and “fascism” peaks in the 1940s, while usage of “communism” reaches an apex around the time of the Cuban Missile Crisis (1962). Beneath the graph is a series of year ranges corresponding to each search term entered into Ngram Viewer; clicking on a range runs a search in Google Books for publications within that range of years that include the search term(s) in question. Click on the image below to enlarge it.
 Ngram Viewer is fun and easy to use. Once you start experimenting with it, it’s hard to stop! More detailed information about Ngram Viewer is available at http://ngrams.googlelabs.com/info. To see an interesting collection of Ngrams submitted by users, go to http://ngrams.tumblr.com/.
Ngram Viewer is fun and easy to use. Once you start experimenting with it, it’s hard to stop! More detailed information about Ngram Viewer is available at http://ngrams.googlelabs.com/info. To see an interesting collection of Ngrams submitted by users, go to http://ngrams.tumblr.com/.


