



[..] events are primarily linguistic or cognitive in nature. That is, the world does not really contain events. Rather, events are the way by which agents classify certain useful and relevant patterns of change.
— Allen and Ferguson, “Actions and Events in Interval Temporal Logic”
What’s an event?
Legislative events — things that take place as part of the legislative process — seem straightforward to define. They are those things that occur in the legislature: meetings, debates, parliamentary maneuvers, and so on. But let’s look at one of the more important words we associate with legislative events: “vote”.
As a noun, it has two meanings:
-
an occasion on which people announce their agreement or disagreement with some proposition;
-
the documentary record of that occasion, expressed as a tally of yeas and nays.
That duality — what happens, versus the record of what happens — creates confusion. We often talk about the documentary record as if it were the process, and vice versa. That creates problems when a community that is primarily concerned with legislative process — consumers of legislative information like staffers on Capitol Hill, members of Congress, and others who work with the process itself — talks to information architects who are primarily concerned with the documentary record. Subtle differences in understanding about what data models represent can lead to real confusion about the capabilities of information retrieval systems. That is particularly true during conversations about design and evaluation.
Here, we have tried to be explicit about when we are speaking about what. Let’s begin with a discussion of modeling problems that pertain to events-as-occasions. A second section treats identifiers for events and how they might be collected and dereferenced. Finally, I’ll look at the incorporation of events into a model of legislative process.
Events as occasions: modeling problems
Useful work on events is found in strange places that, after a moment’s thought, turn out not to be so strange after all. Much of what follows was derived from the event ontology developed at the Center for Digital Music at the University of London — musicians spend a lot of time thinking about things that are embedded in a time-stream, so it’s not surprising that their events model is both detailed and useful. In their world, and ours, events are things that occur at a time and place. They might have duration, but they might also represent an action or change of state for which duration is irrelevant. For example, you could describe the introduction of a bill as something that takes place during a measurable interval that extends over some milliseconds from the time an envelope leaves the hand of the Member introducing the bill until that envelope hits the bottom of the hopper. But that would be silly; some events are simply process milestones or instants that have no duration we need worry about. Most events have participants. Some groups of participants are recurring or somehow formalized; it makes sense to tie events to our models for people and organizations. Other participant groups may be ad hoc groups defined solely in terms of the event (“the people waiting for the 3 o’clock bus”). Finally, things are often products of events : notes produced by a musician playing an instrument, or a pie baked as part of a contest, or a legislative amendment produced in the course of a committee meeting.
Duration and timestamps
Events may have duration, or they may not. “Bill introduction” and “adjournment” are in some sense physical processes that take place in the real world — a piece of paper is placed in a hopper, or a gavel is struck and people gather up their papers and leave the room. Usually, though, we think of them as instantaneous abstractions that refer to a point in a process. By the same token, events may have a duration that is defined with an uncommon use of common language. A “legislative day” is an example of such a thing: it extends between one adjournment of the Senate and the next, which may occupy days or even months in real time.
Participants and their roles
We’ve discussed people and organizations in a separate blog post. Participation in events raises a few other questions about our models for people. In particular, we would stress that people can occupy particular roles with respect to an event, and that those roles may be quite separate from the role that the person occupies within the sponsoring or convening organization. For example, two of the authors recently attended a workshop sponsored by the Committee on House Administration; the convenor was the Technology Policy Director for that organization, and the Committee Chairman was one of the speakers — but he played no leadership role in the workshop itself. Thus, it is necessary to have a set of role properties that describe the individual as that person appears in the context of particular events, perhaps in a way that is different from other roles that that person might play with respect to groups or organizations that are somehow associated with the event.
Location and location defaults
Many events take place somewhere in real space, so event objects need to have attributes that tell us where the event occurs. As with other data about places, we might choose to model these with geographic coordinates, locations drawn from geodata ontologies, or both. But neither of those systems deal particularly well with things like office addresses (“1313 Longworth House Office Building”), which provide location information for the kinds of events we associate with legislative process. Those tend to be expressed as office locations or postal addresses. Examples of purpose-built systems for postal addresses include the Universal Postal Union S42 standard, the vCard ontology, and the W3C PIM standard. Of these, the vCard standard seems to present the best balance of detail and workability, and is incorporated into the http://dvcs.w3.org/hg/gld/raw-file/default/org/index.html .
Often, location information is not explicitly stated, but implicit in the nature of the event itself. “Meeting of the House Ways and Means Committee”, for example, embeds a reliable default assumption about where the meeting is to take place. That is because the meetings always take place in the hearing room that belongs to the committee. It makes sense to model default assumptions about locations as something that is a property of the organization (e.g. “hasDefaultEventLocation”) rather than of any particular event. When information about the event itself is partially or totally incomplete, a location can be inferred via the organizational sponsorship of the event.
Events that collect other events; identifier design
Some events are primarily interesting as collections of other events — for example, a “session” of Congress, which might be seen as a collection of various occurrences on the floor of the legislative chamber, committee meetings, and so on. Moreover, we might want the same event to be visible in very different collections — for example, a particular committee meeting might be part of a calendar, part of a history of meetings of that particular committee, or part of a collection of meetings that different committees have had with respect to a particular bill.
That has implications for identifier design. As we have in other discussions, we would emphasize here the importance of distinguishing between identifiers (URIs) that provide unique, dereferenceable identification of an object (where that object may itself be a collection of other objects), and alternative URIs used solely for convenience of access or for setting up alternative groupings of things. Event identifiers need to be short and opaque; identifiers for collected events can have elaborate (and varied) semantics associated with path elements in the URI. Here are some illustrative examples:
| http://congress.gov/congresses/101/sessions | All sessions of the 101st Congress |
| http://house.gov/congresses/101/sessions/2011/ | First session of the 101st Congress. We believe that the use of the year is more helpful than misleading. |
| http://congress.gov/congresses/101/sessions/2012/events/2012-04-23/votes | All votes taken on 2012-04-23, House or Senate. |
| http://congress.gov/congresses/101/sessions/2012/events/2012-04-23/house/votes | A collection identifier that mirrors the organization of the Congressional Record (though other ordering of the hierarchy would also be sensible) |
| http://congress.gov/congresses/101/house/sessions/2012/votes/[vote-number] | An individual identifier for a vote (House roll call vote numbering runs with the session) |
| http://congress.gov/congresses/101/house/committees/events/hearings | All hearings before House committees for the 101st Congress |
Even this limited set of examples shows that consistency, on one hand, and thorough coverage of imaginable use cases, on the other, will require a lot of painstaking work if they are to be achieved simultaneously. Different — and possibly inconsistent — orderings of the collection hierarchy make sense for different purposes. For example, should the committee information come first in the path hierarchy, or the type of committee event? For some users, ../events/hearings/committees/Judiciary makes more sense than ../committees/Judiciary/events/hearings , and so on. Which of these pathways will be “real” unique identifiers, and which should just represent access pathways to the information?
Documentary products
Events produce things. Most interesting to us, legislative events tend to produce documents that were either themselves the “subject” of the event (as in floor debate over a particular bill) or its result (as when a committee markup session produces a new version of a bill).
The role of the document (or the more abstract notion of a “bill” or “resolution” of which it is the expression) as a value for an “aboutness” property is problematic. As we have remarked elsewhere, bills often have multiple provisions on widely different topics, and a bill’s identifier would be potentially confusing or unhelpful as the sole value offered as, say, the “subject” of a debate. At the same time, it is quite legitimate to say that the bill is what the debate is “about”, in the sense that the bill number would no doubt appear in any headline or agenda entry used for a description of the event — regardless of whether a single word of the discussion actually was about any part of the bill itself, or whether it was a more general discussion about an issue that the bill was meant to address, or was an occasion for a partisan attack on another party. It might thus be wise to distinguish the “agenda item for the discussion” from “the subject of the discussion” in some way.
Modeling the proper relationships between a sequence of events and the documentary workflow that more-or-less tightly reflects it is, then, a more difficult thing. The next section discusses that problem in some detail.
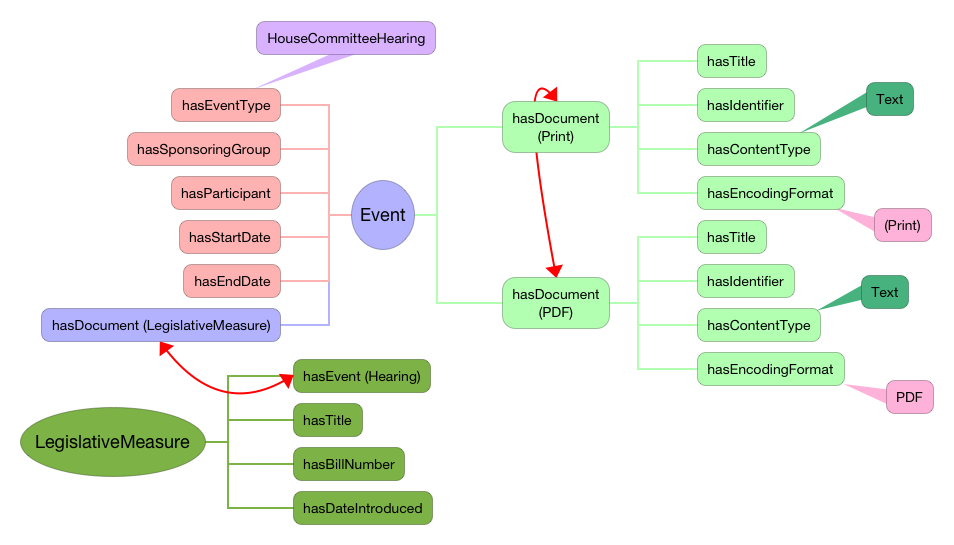
Events, legislative process, and documentary workflow
Events are components of any legislative process model. It is important to think about the ways that clusters or sequences of events form narratives about the legislative process, and the ways in which events can be tied to the documents that the legislative process creates. Prior attempts to integrate an events model with legislative documentation have primarily been concerned with problems of versioning and of legislative applicability or effect. Here, we’re talking about the process of document creation.
Existing ways of modeling — or even discussing — what happens to a measure as it makes its way through Congress are characterized by some confusion between closely connected approaches that are, nevertheless, subtly different. Broadly, those approaches might be divided into subtly different three types:
-
A process-aware model, in which documents are seen as artifacts produced by particular actions or processes within the legislature. (On that view, a “measure” is something of an abstraction that groups a series of bill or resolution texts created during the legislative process, as well as related documentary artifacts such as amendments, signing statements, and so on). Such a model might be one of two types:
-
A model that identifies major stages and events of interest to both legislative insiders and the public. Examples might include the THOMAS vocabulary for bill stages, or the steps represented in a simplified infographic created for public education.
-
Finer-grained, events-based models that divide the legislative process into minutely detailed steps needed by particular communities, for example those interested in the activities of Congressional committees.
-
-
A “legislative process” model containing parliamentary process detail. From a distance, this approach looks a lot like a fine-grained version of the process-aware model just mentioned. But it is far more detailed in its treatment of parliamentary procedure, rules for debate, and other turns and twists primarily of short-term interest to Congressional insiders. That is the type of story told, for example, by the CRS report on resolving differences between House and Senate bill versions. Pieces of such an approach show up in the bill-status attribute used by the House for its XML schemas and DTDs, which contains such status indicators as “held-at-desk-House” and “reengrossed-amendment-Senate”.
-
A “workflow” model, which focuses on the actual flow, versioning, and exchange of documents or other work product. Such a document-centric model has obvious intersections (and points of confusion) with a “process-aware” model, in which major legislative events tend to produce important versions of documents. It also intersects the “legislative process” model, in which certain parliamentary actions (such as amendment) provoke the production of particular documents.
Most of the existing vocabularies in use — which tend to use words like “status” or “stage” to describe their components — use more than one of these approaches at the same time. That creates subtle confusion. Each of the approaches views the world a little differently, and mixing them creates inconsistencies. An illustration of such a mixed model is provided by the “bill stage” vocabulary from GPO, which contains aspects of the process-aware model (“Considered and Passed House”), the legislative process model (“Additional Sponsors House”), and the workflow model (“Amendment Ordered to be Printed Senate”) all at once.
We have taken a process-aware approach to create our models, for several reasons. We have tried to map as much useful detail as possible, while avoiding the many pitfalls inherent in trying to over-think and over-model. An excessively detailed approach focussed on particular parts of the process tends to skew the usefulness of the resulting model in favor of a limited number of specialized users. Also, excessive detail in any or all aspects of such a system inevitably results in a model too cumbersome to be used or maintained:
-
Too-fine distinctions between identifiers will become confused and misapplied, both by maintainers and users.
-
Many identifiers thought useful will end up being dismissed as over-specific, leading to inefficiency and eventually, further confusion.
-
The level of technical expertise required to implement and maintain a too-highly-detailed model will become limited to far too few individuals to guarantee its proper use.
-
Finally, the time and expense involved in too great a level of detail will, in the end, render it of limited usefulness.
Instead, we have tried to provide a model that is “just right” in its level of detail, while acknowledging that our decisions about the various trade-offs involved in such an approach would not be everyone’s. The model has been created with an inherent extensibility that ensures that others may later add any level of specialized detail that they need.
Beyond avoiding problems with excessive detail, such an approach has a few virtues:
-
Conformance with (and respect for) existing systems. It will probably come as no surprise that most of the existing systems that track legislative information agree as to the major features of the process. So do most of the helpful narratives — such as HOLAM and a wide array of CRS reports — that inform people about the process. With such obvious landmarks in common view, it would be a mistake to suggest a map that ignores the landmarks that everyone sees and agrees on.
-
Interoperability. Using a coarser-grained, process-aware model requires a willingness to compromise a level of specialized meaning that might be achieved through the use of more specialized objects, relationships, and identifiers at every stage of the process. However, the compromises are not so great. The interoperability that results from making use of existing systems and standards more than compensates for them. We believe that most of those who currently track legislative information will be able to find obvious points of correspondence and linkage for their own systems.
-
Clarity. Our process-aware approach provides a means of clearly tying the document model to the process model without creating confusion. Our bifurcated audience looks at events in quite different ways. Researchers see events in the context of the legislative process, and focus on the aspects of the events that are of most interest to them, whether it be votes, committee activities, or some other point of interest. Librarians, on the other hand, think of events in the context of their documentary evidence, whether physical or digital, because their descriptive traditions are based on documents. In a very real sense, we see our mission as bringing those two points of view closer together, by using the power of linking to make it possible for members of each audience to find what they need and relate the available resources together in various ways.
As always, we close with musical selections:
-
http://www.youtube.com/watch?v=oNCN1Qx_Myw ( Only the band name is relevant, but what the hell, I couldn’t resist)
Where to look for more
-
Useful ontologies and standards
-
Wolf, Misha, and Charles Wicksteed. “Date and Time Formats”. Online at http://www.w3.org/TR/NOTE-datetime
-
Halpin, Harry et al., “Representing vCard Objects in RDF”. Online at http://www.w3.org/Submission/vcard-rdf/ .
-
Raimond, Yves, and Samer Abdallah. “The Events Ontology”. Online at http://motools.sourceforge.net/event/event.html
-
Raimond, Yves, and Samer Abdallah. “The Timeline Ontology”. Online at http://motools.sourceforge.net/timeline/timeline.html
-
-
Approaches to Legislative Data
-
Boer, Winkels, van Engers, and De Maat, “A Content Management System based on an Event-based Model of Version Management Information in Legislation”, available at http://liicr.nl/IkuT6c .
-
