



VoxPopuLII
A new style of legal research
An attorney/author in Baltimore is writing an article about state bans of teachers’ religious clothing. She finds one of the tersely written statutes online. The website then does a query of its own and tells her about a useful statute she wasn’t aware of—one setting out the permitted disciplinary actions. When she views it, the site makes the connection clear by showing her the where the second statute references the original. This new information makes her article’s thesis stronger.
Meanwhile, 2800 miles away in Oregon, a law student is researching the relationship between the civil and criminal state codes. Browsing a research site, he notices a pattern of civil laws making use of the criminal code, often to enact civil punishments or enable adverse actions. He then engages the website in an interactive text-based dialog, modifying his queries as he considers the previous results. He finally arrives at an interesting discovery: the offenses with the least additional civil burdens are white collar crimes.
A new kind of research system
A new field of computer-assisted legal research is emerging: one that encompasses research in both the academic and the practical “legal research” senses. The two scenarios above both took place earlier this year, enabled by the OregonLaws.org research system that I created and which typifies these new developments.
Interestingly, this kind of work is very recent; it’s distinct from previous uses of computers for researching the law and assisting with legal work. In the past, techniques drawn from computer science have been most often applied to areas such as document management, court administration, and inter-jurisdiction communication. Working to improve administrative systems’ efficiency, people have approached these problem domains through the development of common document formats and methods of data interchange.
The new trend, in contrast, looks in the opposite direction: divergently tackling new problems as opposed to convergently working towards a few focused goals. This organic type of development is occurring because programming and computer science research is vastly cheaper—and much more fun—than it has ever been in the past. Here are a couple of examples of this new trend:
“Computer Programming and the Law”
Law professor Paul Ohm recently wrote a proposal for a new “interdisciplinary research agenda” which he calls “Computer Programming and the Law.” (The law review article is itself also a functioning computer program, written in the literate programming style.) He envisions “researcher-programmers,” enabled by the steadily declining cost of computer-aided research, using computers in revolutionary ways for empirical legal scholarship. He illustrates four new methods for this kind of research: developing computer programs to “gather, create, visualize, and mine data” that can be found in diverse and far-flung sources.
“Computational Legal Studies”
Grad students Daniel Katz and Michael Bommarito (researcher-programmers, as Paul Ohm would call them) created the Computational Legal Studies Blog in March, 2009. The web site is a growing collection of visualization applied to diverse legal and policy issues. The site is part showcase for the authors’ own work and part catalog of the current work of others.
OregonLaws.org
I started the OregonLaws.org project because I wanted faster and and easier access to the 2007 Oregon Revised Statutes (ORS) and other primary and secondary sources. I had a couple of very statute-heavy courses (Wills & Trusts, and Criminal Law) and I frequently needed to quickly find an ORS section. But as I got further into the development, I realized that it could become a platform for experimenting with computational analysis of legal information, similar to the work being done on the Computational Legal Studies Blog.
I developed the system using pretty much the the steps that Paul Ohm discussed:
- Gathering data: I downloaded and cleaned up the ORS source documents, converting them from MS Word/HTML to plain text;
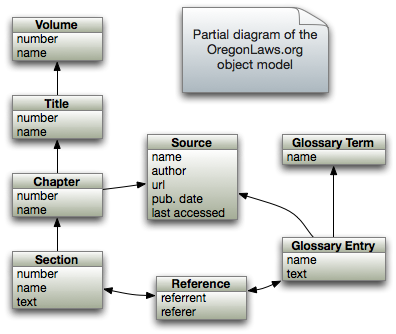
- Creating: I parsed the texts, creating a database model reflecting the taxonomy of the ORS: Volumes, Titles, Chapters, etc.;
- Creating: I created higher-level database entities based on insights into the documents. For example, by modeling textual references between sections explicitly as reference objects which capture a relationship between a referrer and a referent, and;
- Mining and Visualizing: Finally, I’ve begun making web-based views of these newly found objects and relationships.
The object database is the key to intelligent research
By taking the time to go through the steps listed above, powerful new features can be created. Below are some additions to the features described in the introductory scenarios:
We can search smarter. In a previous VoxPopulii post, Julie Jones advocates dropping our usual search methods, and applying techniques like subject-based indexing (a la Factiva’s) to legal content.
This is straightforward to implement with an object model. The Oregon Legislature created the ORS with a conceptual structure similar to most states: The actual content is found in Sections. These are grouped into Chapters, which are in turn grouped into Titles. I was impressed by the organization and the architecture that I was discovering—insights that are obscured by the ways statutes are traditionally presented.

And so I sought out ways to make use of the legislature’s efforts whenever it made sense. In the case of search results, the Title organization and naming were extremely useful. Each Section returned by the search engine “knows” what Chapter and Title it belongs to. A small piece of code can then calculate what Titles are represented in the results, and how frequently. The resulting bar graph doubles as an easy way for users to specify filtering by “subject area”. The screenshot above shows a search for forest.
The ORS’s framework of Volumes, Titles, and Chapters was essentially a tag cloud waiting to be discovered.
We can get better authentication. In another VoxPopulii post, John Joergensen discussed the need for authentication of digital resources. One aspect of this is showing the user the chain of custody from the original source to the current presentation. His ideas about using digital signatures are excellent: a scenario of being able to verify an electronic document’s legitimacy with complete assurance.

We can get a good start towards this goal by explicitly modeling content sources. A source is given attributes for everything we’d want to know to create a citation; date last accessed, URL available at, etc. Every content object in the database is linked to one of these source objects. Now, every time we display a document, we can create properly formatted citations to the original sources.
The gather/create/mine/visualize and object-based approaches open up so many new possibilities, they can’t all be discussed in one short article. It sometimes seems that each new step taken enables previously unforeseen features. A few these others are new documents created by re-sorting and aggregating content, web service APIs, and extra annotations that enhance clarity. I believe that in the end, the biggest accomplishment of projects like this will be to raise our expectations for electronic legal research services, increase their quality, and lower their cost.
 Robb Shecter is a software engineer and third year law student at Lewis & Clark Law School in Portland, Oregon. He is Managing Editor for the Animal Law Review, plays jazz bass, and has published articles in Linux Journal, Dr. Dobbs Journal, and Java Report.
Robb Shecter is a software engineer and third year law student at Lewis & Clark Law School in Portland, Oregon. He is Managing Editor for the Animal Law Review, plays jazz bass, and has published articles in Linux Journal, Dr. Dobbs Journal, and Java Report.
VoxPopuLII is edited by Judith Pratt.
[…] piece from Robb Shecter, the creator of OregonLaws.org: The Recipe for Better Legal Information Services at the VoxPopuLII […]
[…] will see value in using price or usability to gain market share. Lewis & Clark law student (and VoxPopuLII author) Robb Shecter recently introduced OregonLaws.org, a free repository of Oregon law that currently […]
[…] discusses his development approach in his post The Recipe for Better Legal Information Services, at the VoxPopuLII blog, published by Cornell’s Legal Information […]
[…] [Editor’s Note: For documentation, schemas, and controlled vocabularies respecting LexML Brazil, please see the LexML Brazil Project Website. For more information on these issues, please see the following VoxPopuLII posts: John Sheridan on Legislation.gov.uk, Ivan Mokanov on CANLII’s innovative legal citation system, Joe Carmel on LegisLink, and Robb Shecter on OregonLaws.org.] […]
[…] discuss some of the site’s inner workings in The Recipe for Better Legal Information Services at Cornell Law School’s VoxPopuLii. OregonLaws.org Object Model You can follow any […]
[…] discuss some of the site’s inner workings in The Recipe for Better Legal Information Services at Cornell Law School’s […]
[…] discuss some of the site’s inner workings in The Recipe for Better Legal Information Services at Cornell Law School’s […]