



The other day a friend came to me because he heard about the openlaws.eu project. He said: “Hey, openlaws sounds great – does that mean that I can write my own laws now?”. I had to tell him no, but that it was almost as good as that… Continue reading »
VoxPopuLII
New voices in legal information
Oct 252011
 In this post I describe the process and requirements that eventually led to the MetaLex Document Server, a server that hosts all versions of Dutch national statutes and regulations published since May 2011, both as CEN MetaLex, and as Linked Data. Before I set out to do so, however, I would like to emphasize that, although the development of the server and its contents was a one-man-job, the road to make it possible surely was not solitary. A couple of people I’d like to mention here are Alexander Boer, Radboud Winkels, and Tom van Engers of the Leibniz Center for Law, together with whom I have worked over the past ten years to develop, test, and publish the ideas that underlie CEN MetaLex. Also, the team around legislation.gov.uk clearly has done a lot of great and inspiring work in this area.
In this post I describe the process and requirements that eventually led to the MetaLex Document Server, a server that hosts all versions of Dutch national statutes and regulations published since May 2011, both as CEN MetaLex, and as Linked Data. Before I set out to do so, however, I would like to emphasize that, although the development of the server and its contents was a one-man-job, the road to make it possible surely was not solitary. A couple of people I’d like to mention here are Alexander Boer, Radboud Winkels, and Tom van Engers of the Leibniz Center for Law, together with whom I have worked over the past ten years to develop, test, and publish the ideas that underlie CEN MetaLex. Also, the team around legislation.gov.uk clearly has done a lot of great and inspiring work in this area.
So, what happened? Over the course of last spring, I was involved in several small-scale projects that shared a specific need: version-aware identifiers for all parts of legislative texts. The first of these was a report for the Swiss Federal Chancellery on possible technological solutions for a regulation drafting system to be used by the Swiss government. Second to arrive on my desk was a project for the Dutch Tax and Customs Administration (Belastingdienst), in which we were asked to develop a concept-extraction toolkit that would allow them to make explicit where concepts are defined, where they are reused, and how they relate to other concepts (e.g., from an external thesaurus). The purpose of this project was to investigate whether we could replace with technology what is currently a manual process of turning legislation into business processes that fuel citizen- and business-oriented services. The Belastingdienst needs this to better cope with the yearly changes to tax regulation issued by the Ministry of Finance. The Dutch Immigration and Naturalisation Service (IND) faces exactly the same problem: of discovering what part of their business processes is affected by each legislative modification. Updates to legislation require continuous, significant investment in IT re-engineering.
The root of the problem
But don’t modern European governments already have elaborate facilities for supporting this workflow? I’m afraid not.
Currently, regulation drafting is a process of sending around Word documents, copy-and-pasting from older texts, “version hell,” signing by a Minister, and sending the enacted regulations off to a publisher, who will then turn it into some XML format to feed a publishing platform to generate HTML, PDF, and paper versions of the texts. This process is not designed with a content management perspective, and most if not all metadata is thrown away in the process.
Part of the problem is one of organisational change: convincing legislative drafters to use a more structured approach in their daily work. The Dutch Ministry of Security and Justice is currently developing a legislative editing environment (similar to the MetaVex editor developed at the University of Amsterdam), but it will take awhile before this is adopted in practice.
Requirements
To develop a chain of tools for managing legal information, both as text and as knowledge models, we need to address a number of key requirements:
- An integrated legislative drafting and editing environment that supports advanced version and provenance tracking (e.g., version tracking of successive changes to draft texts). Provenance information is very important for eliciting the procedure that led to an official version (both pre- and post-publication), as well as its underlying motivation.
- A format in which these texts are stored that is flexible enough to allow both editing and publication to various formats (such as PDF and HTML).
- The ability to persistently identify every element of a legal text. Versioning of texts, references, and metadata requires identifiers that reflect the different versions of these resources. The various parts of a text should be versioned independently, allowing for transitory regimes.
A versioning mechanism should distinguish between a regulation text as it exists at a particular time, and the final regulation. The IFLA Functional Requirements for Bibliographic Records (FRBR) (Saur, ’98) makes the following distinctions: the work as a “distinguishable intellectual or artistic creation” (e.g., the constitution); the expression as the “intellectual or artistic form that a work takes each time it is realised” (e.g., “The Constitution of July 15th, 2008”); the manifestation as the “physical embodiment of an expression of a work” (e.g., a PDF version of “The Constitution of July 15th, 2008”); and the item as a “single exemplar of a manifestation” (e.g., the PDF version of “The Constitution of July 15th, 2008” residing on my USB stick).
- These identifiers should be dereferenceable to the element they describe, or a description of the element’s metadata.
- Metadata and annotations should be traceable to the most detailed part of a text, as well as to its version, when needed. The same requirement holds for references between texts, allowing for fine-grained analysis of interdependencies between texts.
- It is furthermore a requirement that these identifiers be transparent and follow a prescribed naming convention. This allows third parties to construct valid identifiers without having to first query a name service.
- The metadata itself should be made accessible in a standard format as well.
Making do with what we’ve got
As we don’t have any time to waste, and have neither the organisational infrastructure, nor the funds, to use or develop any other (richer) information source, we need to make do with what’s currently available. How hard is it to build a chain of tools that meets at least part of these requirements? And, what information does the Dutch government already provide on which we can build the services that it itself so dearly needs?
![]()
Wetten.overheid.nl is the de facto source for legislative information in The Netherlands. Users can perform a full text search through the titles and text of all statutes and regulations of the Kingdom of the Netherlands. They can search for a specific article, as well as for the version of a text as it stood at a specified date. Wetten.overheid.nl also provides an API for retrieving XML manifestations of statutes and regulations.
Identifiers
What about identifiers? Wetten.nl supports deeplinks to particular versions of statutes and regulations, but is not very consistent about it. For example:
http://wetten.overheid.nl/cgi-bin/deeplink/law1/bwbid=BWBR0005416/article=6/date=2005-01-14
and
both point to article 6 of the Municipal law, as it was in effect on January 14th, 2005. A third mechanism for identifying regulations is the Juriconnect standard for referring to parts of statutes and regulations. XML documents hosted by Wetten.nl use these identifiers to specify citations between statutes and regulations. For instance, the Juriconnect identifier for article 6 of the Municipal law is:
1.0:c:BWBR0005416&artikel=16&g=2005-01-14
But… the standard does not prescribe a mechanism for dereferenecing an identifier to the actual text of (part of) a statute or regulation.
The BWB XML service and format
XML manifestations of statutes and regulations are retrievable through an API on top of the “Basiswettenbestand” (BWB) content management system. This REST Web service only provides the latest version of an entire statute or regulation. The BWB XML document returned is stripped of all version history: it does not even contain the version date of the text itself.
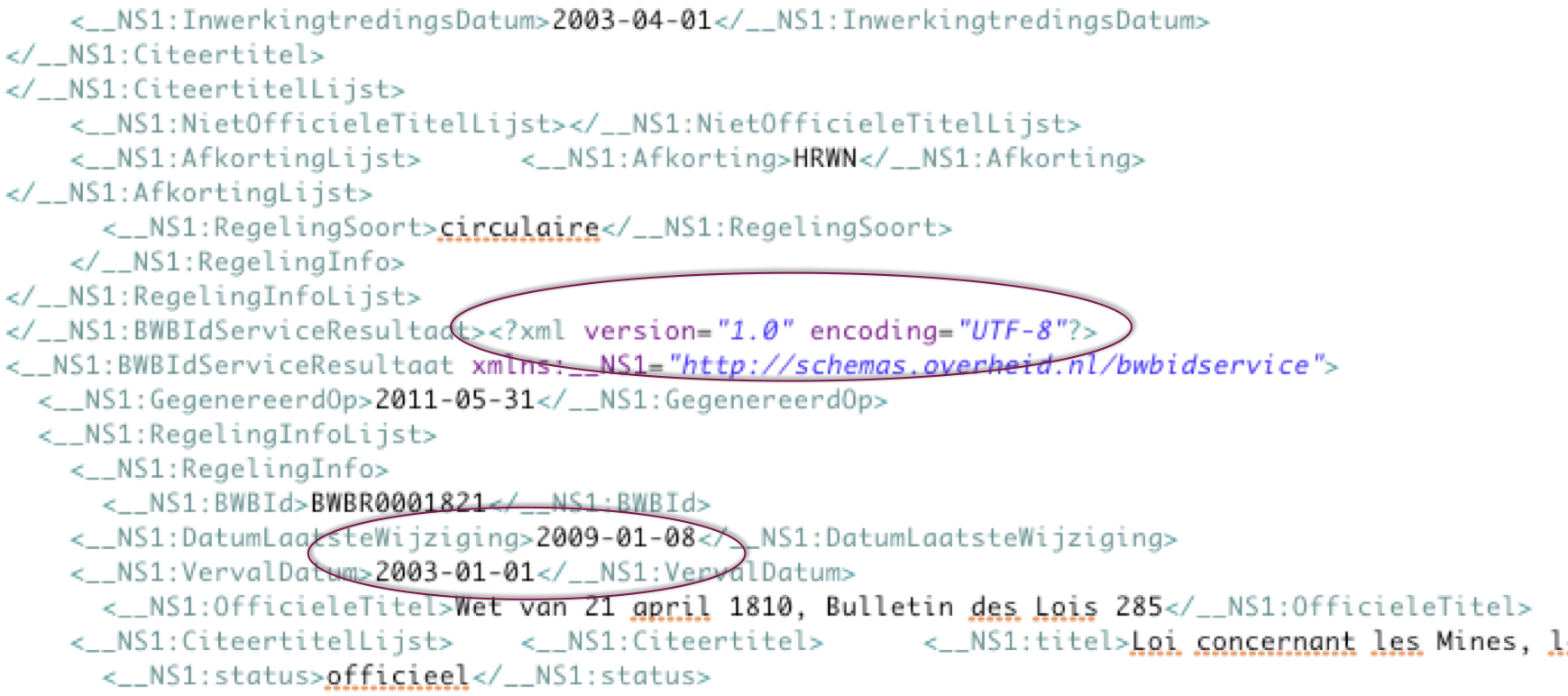
An index of all BWB identifiers, with basic attributes such as official and abbreviated titles, enactment and publication dates, retroactivity, etc. is available as a zipped XML dump or a SOAP service. Unfortunately, the XML file is corrupt, and the date of the latest change to a statute or regulation reported in the index is not really the date of the latest modification, but of the latest update of the statute or regulation in the CMS. See the picture above.
The BWB uses its own XML schema for storing statutes and regulations; this schema does not allow for intermixing with any third-party elements or attributes, ruling out obvious extensions for rich annotations such as RDFa. And, BWB XML elements do not carry any identifiers.
A more general XML format: CEN MetaLex
CEN MetaLex is a jurisdiction-independent XML format for representing, publishing, and interchanging legal texts. It was developed to allow traceability of legal knowledge representations to their original source. MetaLex elements are purely structural. Syntactic elements (structure) are strictly distinct from the meaning of elements by specifying for each element a name and its content model. What this essentially does is to pave the way for a semantic description of the types of content of elements in an XML document. The standard prescribes the existence of a naming convention for minting URI-based identifiers for all structural elements of a legal document. MetaLex explicitly encourages the use of RDFa attributes on its elements, and provides special metadata-elements for serialising additional RDF triples that cannot be expressed on structural elements themselves. MetaLex includes an ontology, which defines an event model for legislative modifications. The legislation.gov.uk portal has adopted the MetaLex event model for representing modifications.
Getting from BWB to CEN MetaLex
The MetaLex schema is designed to be independent of jurisdiction, which means that it should be possible to map each legacy XML element to a MetaLex element in an unambiguous fashion. Fortunately, we were able to define a straightforward 1:n mapping between BWB and MetaLex (see below) by a semi-automatic conversion of the BWB XML DTD.
The transformation of legacy XML to MetaLex and RDF is implemented in the MetaLex converter, an open source Python script available from GitHub. Conversion occurs in four stages:
- mapping legacy elements to MetaLex elements,
- minting identifiers for newly created elements,
- producing metadata for these elements, and
- serialising to appropriate formats.
Step 1: Mapping
For the transformation of BWB XML files, the converter is sequentially fed with all BWB XML files and identifiers listed in the BWB ID index. Based on the mapping table, the converter traverses the DOM tree of the source document, and synchronously builds a DOM tree for the target document. In cases where the MetaLex schema doesn’t quite “fit,” the converter has to make additional repairs.
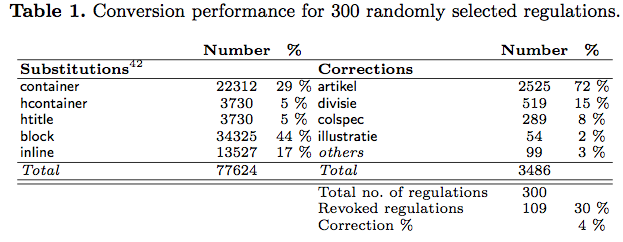
We evaluated the ability of MetaLex to map onto the BWB XML by running the converter on 300 randomly selected BWB identifiers. The artikel element accounts for 72% of all corrections, and corresponds to 68% of all htitle substitutions (5 % of total). This means that only a very small part of BWB XML does not directly fit onto the MetaLex schema. The main cause for incompatibility is the restriction in MetaLex that hcontainer elements are not allowed to contain block elements (and that’s perhaps something to consider for the MetaLex workshop).
Because of the limitations of the API, version information, citation titles, and other metadata are retrieved through a custom-built scraper of the information pages on the wetten.nl Website.
Step 2: Minting Identifiers
For every element in the document we create transparent URL-like URIs for the work, expression and manifestation levels, and two opaque URIs for the expression and item levels in the FRBR specification.
For transparent URIs, we use a naming scheme that is based on the URIs used at legislation.gov.uk, with slight adaptations to allow for the Dutch situation. In short, work level identifiers are based on the standard BWB identifier, followed by a hierarchical path to an element in the source, e.g., “chapter/1/article/1”. These URIs are extended to expression URIs by appending version and language information. Similarly, manifestation URIs are extensions of expression URIs that specify format information such as XML, RDF, etc. Juriconnect references in the source BWB XML are automatically translated to this naming scheme.
The opaque version URI is needed to distinguish different versions of a text. The current Webservice does not provide access to all versions of statutes and regulations (only to the latest), let alone at a level of granularity lower than entire statutes or regulations. We therefore need some way of constructing a version history by regularly checking for new versions, and comparing them to those we looked at before. By including in the opaque URI a unique SHA1 hash of the textual content of an XML element, and simultaneously maintaining a link between the opaque URI and the transparent identifier, different expressions of a work can be automatically distinguished through time. This is needed to work around issues with identifiers based on numbers: the insertion of a new element can change the position (and therefore the identifier) of other elements without a change in the content of the elements.
By this method, globally persistent URIs of every element in a legal text can be consistently generated for both current and future versions of the text. By simultaneously generating an opaque and a transparent expression level URI, identification of these text versions does not have to rely on numbering.
Step 3: Producing Metadata
The MetaLex converter produces three types of metadata. First, legacy metadata from attributes in the source XML is directly translated to RDF triples. Second, metadata describing the structural and identity relations between elements is created. This includes typing resources according to the MetaLex ontology, e.g., as ml:BibliographicExpression; creating ml:realizes relations between expressions and works; and creating owl:sameAs relations between opaque and transparent expression URIs. The official title, abbreviation, and publication date of statutes and regulations are represented using the dcterms:title, dcterms:alternative and dct:valid properties.
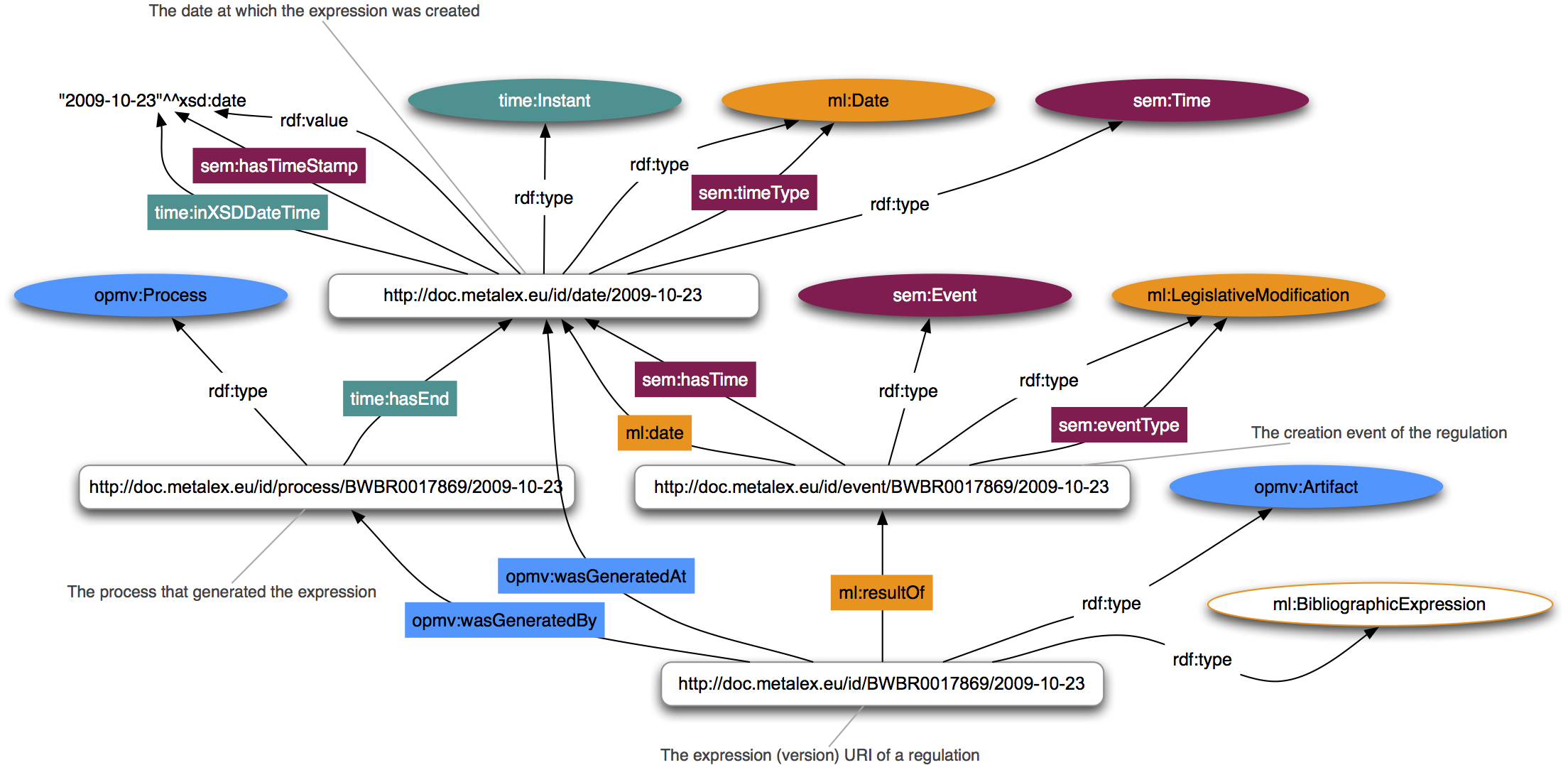
Events and Processes
Event information plays a central role in determining what version of a regulation was valid when. Making explicit which events and modifying processes contributed to an expression of a regulation provides for a flexible and extensible model. The MDS uses the MetaLex ontology for legislative modification events, the Simple Event Model (SEM) and the W3C Time Ontology for an abstract description of events and event types, and the Open Provenance Model Vocabulary (OPMV) for describing processes and provenance information. These vocabularies can be combined in a compatible fashion, allowing for maximal reuse of event and process descriptions by third parties that may not necessarily commit to the MetaLex ontology.

Step 4: Serialization
The MetaLex converter supports three formats for serialising a legal text to a manifestation: the MetaLex format itself, viewable in a browser by linking a CSS stylesheet; RDFa, Turtle and RDF/XML serializations of the RDF metadata; and a citation graph. The converter can automatically upload RDF to a triple store through either the Sesame API, or SPARQL updates. The citation graph is exported as a ‘”net” network file, for further analysis in social network software tools such as Pajek and Gephi. We are exploring ways to use these networks for determining the importance of articles (in degree) and the dependency of legislation on certain articles (betweenness centrality), and for analysing the correlation between legislation and case law.
Publication
The results of this procedure are published through the MetaLex Document Server (MDS). The server follows the Cool URIs specification, and implements HTTP-based redirects for work- and expression-level URIs to corresponding manifestations based on the HTTP accept header. Requests for an HTML mime-type are redirected to a Marbles HTML rendering of a Symmetric Concise Bounded Description (SCBD) of the RDF resource. Similarly, requests for RDF content return the SCBD itself; supported formats are RDF/XML and Turtle. A request for XML will return a snippet of MetaLex for the specified part of a statute or regulation.
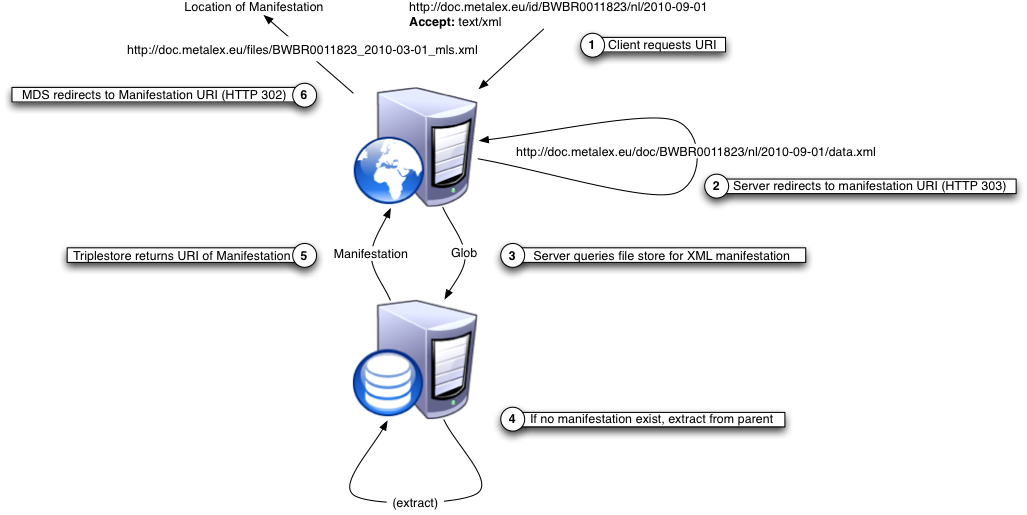
The MDS provides two convenient methods for retrieving manifestations of a statute or regulation. Appending “/latest” to a work URI will redirect to the latest expression present in the triple store. Appending an arbitrary ISO date will return the last expression published before that date if no direct match is available. Lastly, the MDS offers a simple search interface for finding statutes and regulations based on the title and version date.
Results and Take Up
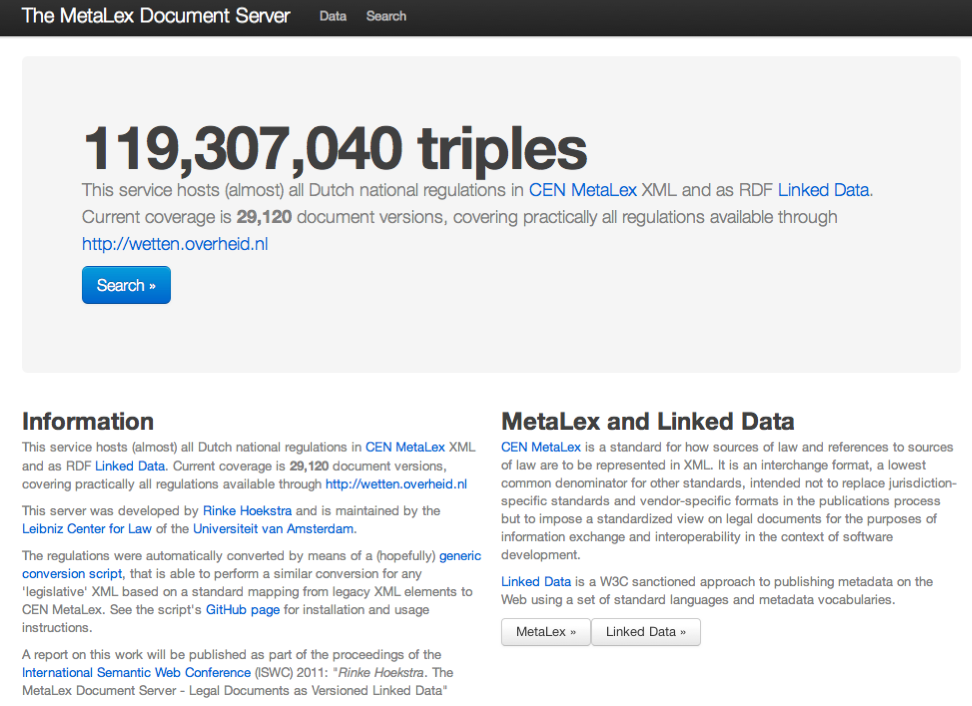 We have been running the converter on a daily basis, on all versions of statutes and regulations made available through the wetten.nl portal since May 2011. This has resulted in a current total of 29,120 document versions: 28 thousand versions in the first run, the rest accumulated through time. For these document versions, we now store 119 million triples of RDF metadata in a 4Store triple store. Compared to the size of legislation.gov.uk (1.9 billion triples, since the 1200s), this is a modest number, but at the current growth rate we will soon need to look for alternative (more professional) solutions. Check the http://doc.metalex.eu Website for the latest numbers.
We have been running the converter on a daily basis, on all versions of statutes and regulations made available through the wetten.nl portal since May 2011. This has resulted in a current total of 29,120 document versions: 28 thousand versions in the first run, the rest accumulated through time. For these document versions, we now store 119 million triples of RDF metadata in a 4Store triple store. Compared to the size of legislation.gov.uk (1.9 billion triples, since the 1200s), this is a modest number, but at the current growth rate we will soon need to look for alternative (more professional) solutions. Check the http://doc.metalex.eu Website for the latest numbers.
I am happy to say, also, that this work has not gone unnoticed. The IND was particularly enthused by the versioning mechanism, and is in the process of adopting the MDS approach as their internal content management system. Similarly, the ability to link concept descriptions to reliably versioned parts of legislation has been an eye opener for the Belastingdienst. We are also in touch with several people at ICTU, the organisation behind Wetten.nl, to help them improve their services.
 Dr. Rinke Hoekstra is a postdoctoral researcher at the Leibniz Center for Law at the University of Amsterdam. He is the developer of the MetaLex Document Server, the principal author of the LKIF Core ontology of basic legal concepts, and one of the initial developers of the MetaLex XML format for legal sources.
Dr. Rinke Hoekstra is a postdoctoral researcher at the Leibniz Center for Law at the University of Amsterdam. He is the developer of the MetaLex Document Server, the principal author of the LKIF Core ontology of basic legal concepts, and one of the initial developers of the MetaLex XML format for legal sources.
VoxPopuLII is edited by Judith Pratt. Editor-in-Chief is Robert Richards, to whom queries should be directed. The statements above are not legal advice or legal representation. If you require legal advice, consult a lawyer. Find a lawyer in the Cornell LII Lawyer Directory.
Oct 062010
In this post, I will describe how natural language processing can help in creating computer systems dealing with the law.
 A lot of computer systems are being designed to help users deal with legal texts — accessing, understanding, or applying them. [Editor’s Note: Michael Poulshock’s Jureeka is an example of a system that automates the application of legal texts.] Other systems — such as DALOS — are about creating legal texts, providing support for the writers, or simulating the effects of a text. Such systems are based on something more than “just” the legal text: there is XML mark-up, an OWL ontology, or a representation of the rules in SWRL or some programming language. This means that any piece of legislation that you want to use on your computer system needs to be translated into this computer representation.
A lot of computer systems are being designed to help users deal with legal texts — accessing, understanding, or applying them. [Editor’s Note: Michael Poulshock’s Jureeka is an example of a system that automates the application of legal texts.] Other systems — such as DALOS — are about creating legal texts, providing support for the writers, or simulating the effects of a text. Such systems are based on something more than “just” the legal text: there is XML mark-up, an OWL ontology, or a representation of the rules in SWRL or some programming language. This means that any piece of legislation that you want to use on your computer system needs to be translated into this computer representation.
We try to support this translation using natural language processing, so that (part of) the translation can be done by a computer. This automation should have a number of advantages. First of all, computers are cheaper than human experts, and automating the process should reduce the amount of resources needed for this task. Second, the models that are produced by automated processes are more consistent; human experts may treat two similar sentences differently, but a computer program will always behave the same. Finally, an approach employing structures ensures that there is a clear mapping between the elements of the computer model and the original text.
Natural Language Processing isn’t perfect yet: computers cannot understand human language. However, legal text is quite structured, and offers a lot more handholds for automated translation than, say, a novel.
Document Structure
The first step that we will have to undertake is to determine the structure of the document. Online services like Legislation.gov.uk and wetten.nl can make it easier to access legal documents because they can point you to the right part of the document (such as a chapter, paragraph, sentence, etc.). In most law texts, the structure has been made explicit using clear headings, like: Chapter 1 or Chapter 1. General Provisions. So, in order to detect structure, we need to detect these headings. This means we’ll need to search the document for lines starting with Chapter, followed by some designation (which we refer to as an index), and perhaps followed by some text – say, the title of the chapter. The index can  be a lot of things: Arabic numbers (1, 2, 3, …), Roman numbers (I, II, III, …) or letters (a, b, c, …). Sometimes the index is an ordinal appearing before the chapter label: First chapter. It may even be a combination of several numbers and letters (5.2a). This is not a great problem, as we can more or less assume that whatever follows the word Chapter is the index.
be a lot of things: Arabic numbers (1, 2, 3, …), Roman numbers (I, II, III, …) or letters (a, b, c, …). Sometimes the index is an ordinal appearing before the chapter label: First chapter. It may even be a combination of several numbers and letters (5.2a). This is not a great problem, as we can more or less assume that whatever follows the word Chapter is the index.
The main problem with this approach is that there are also regular sentences that start with the word Chapter, and we need to separate those out. To do so, we can use some heuristics: A title will not end with a full stop (.); a heading will always start on a new line; etc.
 This procedure to find the headings for chapters is repeated to find headings for sections, subsections, etc. Also, some sections (like numbered paragraphs or list items) will not have a full heading, but just a number, which we also need to recognise. Finally, some sections don’t have a heading but can be recognised because they start with a fixed language pattern. For example, a preamble in a (recent) Dutch Law — such as this — will start with: We, Beatrix, Queen of the Netherlands, Princess of Orange-Nassau, etc. etc. etc.
This procedure to find the headings for chapters is repeated to find headings for sections, subsections, etc. Also, some sections (like numbered paragraphs or list items) will not have a full heading, but just a number, which we also need to recognise. Finally, some sections don’t have a heading but can be recognised because they start with a fixed language pattern. For example, a preamble in a (recent) Dutch Law — such as this — will start with: We, Beatrix, Queen of the Netherlands, Princess of Orange-Nassau, etc. etc. etc.
This procedure assumes that the input for the process is just text. Many documents will contain more information — such as textual markup — and headings may be more easily identified because they are marked as bold text, or even as headings. So, in situations where the input is made up of documents that are marked-up in a consistent way, it may be easier to recognise the patterns by taking layout into account in addition to text.
To actually find the patterns, we can use existing toolkits like GATE. After the patterns have been found, and the structure has been recognised, we can store it using a format such as MetaLex.
References
The second step is to detect the references from a portion of a law text to other portions of that text, or from a law text to other texts. References, like headings, follow a pattern. The simplest patterns are rather similar to headings; the text chapter 13 is probably a reference, unless it is part of a heading.  Just like headings, basic references consist of a label (section, chapter, article) and an index (13, 13.2.1, XIII, m). And, just as with headings, we can find the references by looking for these patterns in the text.
Just like headings, basic references consist of a label (section, chapter, article) and an index (13, 13.2.1, XIII, m). And, just as with headings, we can find the references by looking for these patterns in the text.
However, this is only the simplest form of references. Besides references to a specific section, such as chapter 13, there are of course also references to a complete law. Some of these references follow a pattern as well, such as the law of October 1st, 2007. Most laws are cited by means of a citation title, though, such as the Railroad Act. Such titles can contain all kinds of words, and they don’t follow a strict pattern. Thus, such references cannot be detected using patterns. Instead, we use a list containing all (citation) titles to detect such references.
Other, more complex references contain multiple references in one statement, such as articles 13 and 14, or multiple levels: article 13, item e, of the Railroad Act, or even more complex combinations of the two: articles 13, item e, 14, item f, 15 and 16, items a and b, of the Railroad Act. Though more complex than the simple combination of label and index, these references still follow clear (sometimes recurring) patterns, and can be found in the text by searching for such patterns.
At the Leibniz Center for Law, we’ve created a parser based on these patterns, which had an accuracy of over 95%. For each reference found, we can construct some standardised name, and store it. With this technology, not only can we add hyperlinks to documents; we can also search for documents that refer to some specific document.
Classification
Now that we’ve got the structure and links in place, it’s time to start with the actual meaning of the text. Rather than tackling the entire text as a whole, we’ve selected sentences as the basic building blocks, and we attempt to create computer models for individual sentences first. Later, we can integrate those individual models to a complete model.
As a first step in creating the models, we start by assigning a broad meaning, or classification, to each sentence. Does the sentence give a definition for a concept, describe an obligation, or make a change in another law? In total, we distinguish fourteen different classes of sentences that appear in Dutch law texts. The next step in our automated approach is to assign a class to each sentence automatically.
To do so, we turn once again to language patterns. Legal language is rather strict, and legislative drafters don’t vary their language a lot — in a novel, variation may make for a more appealing text, but in a law, variation invites ambiguity. In fact, there are official Guidelines for Legislative Drafting that (among other things) reduce the variety of texts used. [Editor’s Note: For example, drafters of legislation in the U.S. House of Representatives Office of the Legislative Counsel have used Donald Hirsch’s Drafting Federal Law.] This means that for each of our classes, there’s a rather limited set of language patterns used. For example, definitions will look like one of these:
Under … is understood …
This law understands under … …
There are some variations in word order, but in the end, a small set of patterns is sufficient to describe all commonly used phrases. There is only one class of sentences where we cannot define a full set of patterns: obligations. In Dutch laws, obligations are often expressed without signal words like must or is obliged to. Instead, the obligations are presented as a fact:
No bodies are buried on a closed cemetery.
However, since the obligations are the only sentences lacking all-compassing patterns, we will assume that any sentence that does not mark a pattern is one of these obligations.
Based on the patterns found, we’ve created a classifier that attempts to sort sentences into these different classes. This classifier has an accuracy of 91%, and we expect that this can improved a bit further.
(As a side note: For classification tasks as these, a machine learning approach is often preferred; see, e.g., here. With such an approach, you provide the computer, not with patterns, but with a bunch of sample sentences. The computer will then extract its own patterns from those sentences, and use these to classify any new sentences. We’ve tried this approach as well (using the toolkit WEKA), and reached similarly accurate results.)
Modelling
Having classified the sentences, we now want to create models of the sentences. In essence, this means breaking down each sentence into smaller components and defining relationships between them. In some cases, the patterns used to classify the sentence already give us sufficient information to break up the sentence. Suppose we have a sentence like:
In article 7.12, sub one, second sentence, «article 7.3b» is replaced by: article 7.3c.
We classify this sentence as a replacement because of the text is replaced by. We can then also conclude that the text between angle quotes is the text to be replaced, the text following the colon is the replacing text, and the reference preceding it (which we’ve already detected) is the location where the replacement should take place.
This works fine for sentences that are somehow “about” the law. But for sentences that deal with some other domain, such as taxes, traffic, or commerce, we cannot predict all the elements. These sentences could be about anything — and statutes are full of such sentences. For such sentences, we need to follow a generic method. The aim is to model rules as a situation or action that is allowed or not allowed, similar to the models created in the HARNESS system of the ESTRELLA project. For example, for an obligation, we assume that the sentence describes some action that must be done.  We try to identify who should be doing the action, and what other elements are involved. Thus, for the sentence:
We try to identify who should be doing the action, and what other elements are involved. Thus, for the sentence:
Our Minister issues a warrant to the negligent person.
we would like to extract the following information:
Obligation
Action: Issue
Agent: Our Minister
Patient: Warrant
Recipient: Negligent person
(Such a table, or frame, is not the same as a computer model, but has all the elements needed to create one.)
Now, identifying these different elements of the sentence (agent, patient, recipient) is something that computer linguists have already worked on for a long time, which means we do not have to start from scratch. Instead, we can use existing parsers to do much of the work for us. For our Dutch laws, we use the Alpino parser. 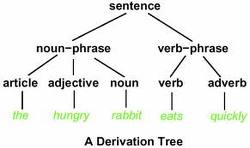 Such a parser will create a parse tree of a sentence. In this parse tree, the sentence will be split up in parts. The parser can identify which part is the subject, the direct object, the indirect object, etc. Based on this information, we can determine the agent, patient, and recipient (so-called semantic roles). In a sentence with a verb in the active voice, the subject is the agent, the direct object is the patient, and the indirect object is the recipient. Furthermore, the parser will determine the relationship between words, such as an adjective that modifies a noun. This information, too, helps us to make more accurate models.
Such a parser will create a parse tree of a sentence. In this parse tree, the sentence will be split up in parts. The parser can identify which part is the subject, the direct object, the indirect object, etc. Based on this information, we can determine the agent, patient, and recipient (so-called semantic roles). In a sentence with a verb in the active voice, the subject is the agent, the direct object is the patient, and the indirect object is the recipient. Furthermore, the parser will determine the relationship between words, such as an adjective that modifies a noun. This information, too, helps us to make more accurate models.
We start out with the output of these parsers, and then try to extract all terms that have some more significance. If we want an application to compute whether or not a situation is allowed, a word like car can be treated in a generic way, but terms like allowed and not some special attention.
To Be Continued…
We still need to refine the method for making these models, and evaluate the results. After that, the individual models will need to be merged. But even as things stand now, we think these tools will help with getting legal text from paper into your computer systems.
[Editor’s Note: For more information about this topic, please see Dr. Adam Wyner’s post, Weaving the Legal Semantic Web with Natural Language Processing.]
 Emile de Maat is a researcher at the Leibniz Center for Law (University of Amsterdam). His research focuses on the automatic extraction of metadata and meaning from legal sources.
Emile de Maat is a researcher at the Leibniz Center for Law (University of Amsterdam). His research focuses on the automatic extraction of metadata and meaning from legal sources.
VoxPopuLII is edited by Judith Pratt. Editor in chief is Robert Richards.