



The other day a friend came to me because he heard about the openlaws.eu project. He said: “Hey, openlaws sounds great – does that mean that I can write my own laws now?”. I had to tell him no, but that it was almost as good as that… Continue reading »
VoxPopuLII
New voices in legal information
1. The Death and Life of Great Legal Data Standards
 Thanks to the many efforts of the open government movement in the past decade, the benefits of machine-readable legal data — legal data which can be processed and easily interpreted by computers — are now widely understood. In the world of government statutes and reports, machine-readability would significantly enhance public transparency, help to increase efficiencies in providing services to the public, and make it possible for innovators to develop third-party services that enhance civic life.
Thanks to the many efforts of the open government movement in the past decade, the benefits of machine-readable legal data — legal data which can be processed and easily interpreted by computers — are now widely understood. In the world of government statutes and reports, machine-readability would significantly enhance public transparency, help to increase efficiencies in providing services to the public, and make it possible for innovators to develop third-party services that enhance civic life.
In the universe of private legal data — that of contracts, briefs, and memos — machine-readability would open up vast potential efficiencies within the law firm context, allow the development of novel approaches to processing the law, and would help to drive down the costs of providing legal services.
However, while the benefits are understood, by and large the vision of rendering the vast majority of legal documents into a machine-readable standard has not been realized. While projects do exist to acquire and release statutory language in a machine-readable format (and the government has backed similar initiatives), the vast body of contractual language and other private legal documents remains trapped in a closed universe of hard copies, PDFs, unstructured plaintext and Microsoft Word files.
Though this is a relatively technical point, it has broad policy implications for society at large. Perhaps the biggest upshot is that machine-readability promises to vastly improve access to the legal system, not only for those seeking legal services, but also for those seeking to provide legal services, as well.
It is not for lack of a standard specification that the status quo exists. Indeed, projects like LegalXML have developed specifications that describe a machine-readable markup for a vast range of different types of legal documents. As of writing, the project includes technical committees working on legislative documents, contracts, court filings, citations, and more.
However, by and large these efforts to develop machine-readable specifications for legal data have only solved part of the problem. Creating the standard is one thing, but actually driving adoption of a legal data standard is another (often more difficult) matter. There are a number of reasons why existing standards have failed to gain traction among the creators of legal data.
For one, the oft-cited aversion of lawyers to technology remains a relevant factor. Particularly in the case of the standardization of legal data, where the projected benefits exist in the future and the magnitude of benefit speculative at the present moment, persuading lawyers and legislatures to adopt a new standard remains a challenge, at best.
Secondly, the financial incentives of some actors may actually be opposed towards rendering the universe of legal documents into a machine-readable standard. A universe of largely machine-readable legal documents would also be one in which it may be possible for third-parties to develop systems that automate and significantly streamline legal services. In the context of the ever-present billable hour, parties may resist the introduction of technological shifts that enable these efficiencies to emerge.
Third, the costs of converting existing legal data into a machine-readable standard may also pose a significant barrier to adoption. Marking up unstructured legal text can be highly costly depending on the intended machine usage of the document and the type of document in question. Persuading a legislature, firm, or other organization with a large existing repository of legal documents to take on large one-time costs to render the documents into a common standard also discourages adoption.
These three reinforcing forces erect a significant cultural and economic barrier against the integration of machine-readable standards into the production of legal text. To the extent that one believes in the benefits from standardization for the legal industry and society at large, the issue is — in fact — not how to define a standard, but how to establish one.
2. Rough Consensus, Running Standards
So, how might one go about promulgating a standard? Particularly in a world in which lawyers, the very actors that produce the bulk of legal data, are resistant to change, mere attempts to mobilize the legal community to action are destined to fail in bringing about the fundamental shift necessary to render most if not all legal documents in a common machine-readable format.
In such a context, implementing a standard in a way that removes humans from the loop entirely may, in fact, be more effective. To do so, one might design code that was capable of automatically rendering legal text into a machine-readable format. This code could then be implemented by applications of all kinds, which would output legal documents in a standard format by default. This would include the word processors used by lawyers, but also integration with platforms like LegalZoom or RocketLawyer that routinely generate large quantities of legal data. Such a solution would eliminate the need for lawyer involvement from the process of implementing a standard entirely: any text created would be automatically parsed and outputted in a machine readable format. Scripts might also be written to identify legal documents online and process them into a common format. As the body of documents rendered in a given format grew, it would be possible for others to write software leveraging the increased penetration of the standard.
There are — obviously — technical limitations in realizing this vision of a generalized legal data parser. For one, designing a truly comprehensive parser is a massively difficult computer science challenge. Legal documents come in a vast diversity of flavors, and no common textual conventions allow for the perfect accurate parsing of the semantic content of any given legal text. Quite simply, any parser will be an imperfect (perhaps highly imperfect) approximation of full machine-readability.
Despite the lack of a perfect solution, an open question exists as to whether or not an extremely rough parsing system, implemented at sufficient scale, would be enough to kickstart the creation of a true common standard for legal text. A popular solution, however imperfect, would encourage others to implement nuances to the code. It would also encourage the design of applications for documents rendered in the standard. Beginning from the roughest of parsers, a functional standard might become the platform for a much bigger change in the nature of legal documents. The key is to achieve the “minimal viable standard” that will begin the snowball rolling down the hill: the point at which the parser is rendering sufficient legal documents in a common format that additional value can be created by improving the parser and applying it to an ever broader scope of legal data.
But, what is the critical mass of documents one might need? How effective would the parser need to be in order to achieve the initial wave of adoption? Discovering this, and learning whether or not such a strategy would be effective, is at the heart of the Restatement project.
3. Introducing Project Restatement
Supported by a grant from the Knight Foundation Prototype Fund, Restatement is a simple, rough-and-ready system which automatically parses legal text into a basic machine-readable JSON format. It has also been released under the permissive terms of the MIT License, to encourage active experimentation and implementation.
The concept is to develop an easily-extensible system which parses through legal text and looks for some common features to render into a standard format. Our general design principle in developing the parser was to begin with only the most simple features common to nearly all legal documents. This includes the parsing of headers, section information, and “blanks” for inputs in legal documents like contracts. As a demonstration of the potential application of Restatement, we’re also designing a viewer that takes documents rendered in the Restatement format and displays them in a simple, beautiful, web-readable version.
Underneath the hood, Restatement is all built upon web technology. This was a deliberate choice, as Restatement aims to provide a usable alternative to document formats like PDF and Microsoft Word. We want to make it easy for developers to write software that displays and modifies legal documents in the browser.
In particular, Restatement is built entirely in JavaScript. The past few years have been exciting for the JavaScript community. We’ve seen an incredible flourishing of not only new projects built on JavaScript, but also new tools for building cool new things with JavaScript. It seemed clear to us that it’s the platform to build on right now, so we wrote the Restatement parser and viewer in JavaScript, and made the Restatement format itself a type of JSON (JavaScript Object Notation) document.
For those who are more technically inclined, we also knew that Restatement needed a parser formalism, that is, a precise way to define how plain text can get transformed into Restatement format. We became interested in recent advance in parsing technology, called PEG (Parsing Expression Grammar).
PEG parsers are different from other types of parsers; they’re unambiguous. That means that plain text passing through a PEG parser has only one possible valid parsed output. We became excited about using the deterministic property of PEG to mix parsing rules and code, and that’s when we found peg.js.
With peg.js, we can generate a grammar that executes JavaScript code as it parses your document. This hybrid approach is super powerful. It allows us to have all of the advantages of using a parser formalism (like speed and unambiguity) while also allowing us to run custom JavaScript code on each bit of your document as it parses. That way we can use an external library, like the Sunlight Foundation’s fantastic citation, from inside the parser.
Our next step is to prototype an “interactive parser,” a tool for attorneys to define the structure of their documents and see how they parse. Behind the scenes, this interactive parser will generate peg.js programs and run them against plaintext without the user even being aware of how the underlying parser is written. We hope that this approach will provide users with the right balance of power and usability.
4. Moving Forwards
Restatement is going fully operational in June 2014. After launch, the two remaining challenges are to (a) continuing expanding the range of legal document features the parser will be able to successfully process, and (b) begin widely processing legal documents into the Restatement format.
For the first, we’re encouraging a community of legal technologists to play around with Restatement, break it as much as possible, and give us feedback. Running Restatement against a host of different legal documents and seeing where it fails will expose the areas that are necessary to bolster the parser to expand its potential applicability as far as possible.
For the second, Restatement will be rendering popular legal documents in the format, and partnering with platforms to integrate Restatement into the legal content they produce. We’re excited to say on launch Restatement will be releasing the standard form documents used by the startup accelerator Y Combinator, and Series Seed, an open source project around seed financing created by Fenwick & West.
It is worth adding that the Restatement team is always looking for collaborators. If what’s been described here interests you, please drop us a line! I’m available at tim@robotandhwang.org, and on Twitter @RobotandHwang.
 Jason Boehmig is a corporate attorney at Fenwick & West LLP, a law firm specializing in technology and life science matters. His practice focuses on startups and venture capital, with a particular emphasis on early stage issues. He is an active maintainer of the Series Seed Documents, an open source set of equity financing documents. Prior to attending law school, Jason worked for Lehman Brothers, Inc. as an analyst and then as an associate in their Fixed Income Division.
Jason Boehmig is a corporate attorney at Fenwick & West LLP, a law firm specializing in technology and life science matters. His practice focuses on startups and venture capital, with a particular emphasis on early stage issues. He is an active maintainer of the Series Seed Documents, an open source set of equity financing documents. Prior to attending law school, Jason worked for Lehman Brothers, Inc. as an analyst and then as an associate in their Fixed Income Division.
 Tim Hwang currently serves as the managing human partner at the offices of Robot, Robot & Hwang LLP. He is curator and chair for the Stanford Center on Legal Informatics FutureLaw 2014 Conference, and organized the New and Emerging Legal Infrastructures Conference (NELIC) at Berkeley Law in 2010. He is also the founder of the Awesome Foundation for the Arts and Sciences, a distributed, worldwide philanthropic organization founded to provide lightweight grants to projects that forward the interest of awesomeness in the universe. Previously, he has worked at the Berkman Center for Internet and Society at Harvard University, Creative Commons, Mozilla Foundation, and the Electronic Frontier Foundation. For his work, he has appeared in the New York Times, Forbes, Wired Magazine, the Washington Post, the Atlantic Monthly, Fast Company, and the Wall Street Journal, among others. He enjoys ice cream.
Tim Hwang currently serves as the managing human partner at the offices of Robot, Robot & Hwang LLP. He is curator and chair for the Stanford Center on Legal Informatics FutureLaw 2014 Conference, and organized the New and Emerging Legal Infrastructures Conference (NELIC) at Berkeley Law in 2010. He is also the founder of the Awesome Foundation for the Arts and Sciences, a distributed, worldwide philanthropic organization founded to provide lightweight grants to projects that forward the interest of awesomeness in the universe. Previously, he has worked at the Berkman Center for Internet and Society at Harvard University, Creative Commons, Mozilla Foundation, and the Electronic Frontier Foundation. For his work, he has appeared in the New York Times, Forbes, Wired Magazine, the Washington Post, the Atlantic Monthly, Fast Company, and the Wall Street Journal, among others. He enjoys ice cream.
 Paul Sawaya is a software developer currently working on Restatement, an open source toolkit to parse, manipulate, and publish legal documents on the web. He previously worked on identity at Mozilla, and studied computer science at Hampshire College.
Paul Sawaya is a software developer currently working on Restatement, an open source toolkit to parse, manipulate, and publish legal documents on the web. He previously worked on identity at Mozilla, and studied computer science at Hampshire College.
VoxPopuLII is edited by Judith Pratt. Editors-in-Chief are Stephanie Davidson and Christine Kirchberger, to whom queries should be directed.
As guest bloggers to this site, we have been asked to write about big ideas. We’ll get to those. But first, a note about hackathons.
Could legal hackathons be like this one day?
Hackathons used to be the exclusive domain of soda-and-coffee-guzzling, pizza-eating, all-night hacking, highly competitive computer programmers. The result of such a hackathon is often supposed to be a cool app (like the forerunner of Twitter) that is even cooler because it was built in the compressed schedule of the event. More recently, hackathons have been popping up in a variety of places, with some unexpected contexts and sponsors including the U.S. House of Representatives, NASA, Brooklyn Law School, New York City government, and others. These events serve as a way to prove (or build) the sponsor’s tech credentials and to cross-fertilize policy and technology expertise. There has been some handwringing and thoughtful commentary about the expansion of “civic” hackathons and what sustainable outcomes they produce.
As co-organizers, with Karen Suhaka, Greg Wilson, Charles Belle and others, of two legislative focused, hackathon-inspired events–the California Law Hackathon, and the International Legislation Un-hackathon–we can attest to their value in bringing engineers and lawyer and policy folks together. We can give some insights into the kinds of benefits these events have had in propelling efforts on legislative data standards, and some of the advances that have taken place in the development of these standards over the last year.
Big Idea: Legislative Data Standards
And now to the big idea: to represent all the world’s legislation in a standard structured data format. That’s actually two big ideas: (1) putting legislation into a structured data format, and (2) designing that format so that it is compatible with the wide variety of laws and legislative document types worldwide.
There are reasons for doing these things: First, introducing structured data to legislation can make it possible to search and analyze the law with greater precision and efficiency. And second, having a common standard can permit more comprehensive bill-tracking and comparison between jurisdictions.
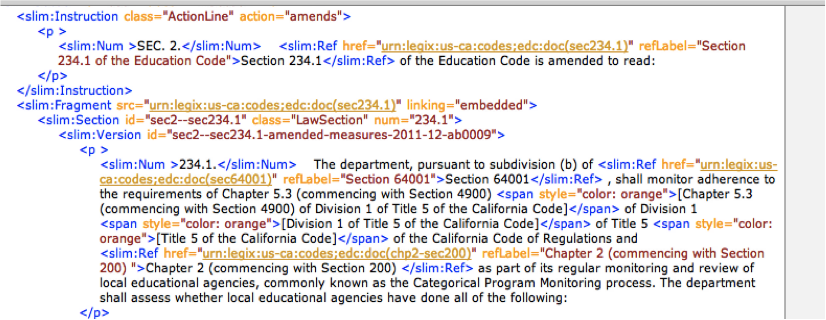
California Bill with Metadata
It also can make it possible for legislatures with small (and shrinking) budgets to benefit from some of the same bill drafting software that is being developed for much larger jurisdictions. (Full disclosure: Xcential has developed such software for more than ten years, including the drafting platform used by the State of California.)
In the age of Google, these ideas may not seem so big; in fact, they are a subset of Google’s far-reaching mission. However, legislation is a corner of the world’s information that Google has not yet addressed in a systematic way. And as regular readers of this blog know, legislation presents its own hurdles, technical and bureaucratic (not necessarily in that order), that make this both an interesting and a challenging problem. One of the challenges is that the kind of people who generally work with data (we’ll call them engineers) and the kind of people who generally work with legislation (we’ll call them lawyers and policy folks) don’t often work on data and legislation together. One of us, a lawyer and policy type, has made this point graphically (and somewhat hyperbolically) in a Quora response to a question about whether version control software could be used for legislation. That question, and a subsequent discussion generated in response to a blogpost by software engineer Abe Voelker about version control for legislation, drew in many engineers and some lawyers and policy folks.
For software engineers who consider such things, it is very attractive to think about treating legal text as if it were software code; we could automatically highlight and cross-validate key terms, run test cases, automate redlining and version control, etc. It would be easy to see what the state of the law was at any particular point in time, and to trace the series of amendments that got us into the mess we’re in today. This desire is often expressed as “What if we had a Github for legislation?” On the other hand, people who work closely with legislation–researching it, drafting it or developing information systems to deal with it–tend to see the many places that the analogy between computer code and legal code break down. Legal texts have been shaped over hundreds of years by technologically conservative institutions, using print-based systems.
The full transformation of law to digital information is not going to happen overnight. While most law is already accessible in electronic format (often pdf), it is not encoded in a way that software engineers could start using their favorite text-munching tools. One of us, an engineer, has described this as the difference between computerization and automation. The move toward better digital tools for automating legislative drafting and research tasks will require more dialogue and working exchanges between engineers and the lawyers and policy folks.
That brings us back to hackathons.
What is a Legislative Hackathon?
Recognizing the need to bring lawyers and engineers together in order to implement our big idea(s), and appreciating the valuable bandwagon that hackathons have become, we decided to jump onboard. The first event we organized, the California Law Hackathon, was hosted just over a year ago, in September 2011, in Berkeley at the offices of Maplight, and in Denver by Karen Suhaka’s team at BillTrack50. The event focused on building web-based visualization tools to track the timeline of amendments to California legislation, and to link particular amendments, through their legislative sponsors, to particular donors or interest groups. We were joined remotely by a number of international participants, including John Sheridan, head of e-services for legislation.gov.uk, and a fellow guest contributor to this blog. As one participant noted, we learned a great deal at the event, including the limits placed on us by the existing data. Neither the legislative record, nor the donations databases are detailed enough to trace influence in politics in the way we hoped. This helped spark an interest in a more in-depth exploration of legislative data formats, and in particular how more and better metadata could be added to legislation.
That led to the International Legislation Un-hackathon, held simultaneously at UC Hastings, Stanford and Denver, with participants from the University of Bologna (Ravenna campus) and around the world. So assuming you can get engineers together with lawyers and policy folks, what do you do with them? We decided that we’d need a user-friendly tool that could be used to explore and add metadata to legislation from around the world. This could highlight a developing legislative XML standard, Akoma Ntoso (more about this standard soon), and give hands-on experience to lawyer and policy types kinds of text and analysis tools that engineers take for granted.
Hacking With A Legislative Editor
So one of us (the engineer, naturally) started building a web-based editor for legislation, while the other (the lawyer, naturally) started organizing the next hackathon. Of course, thought the lawyer, it would just
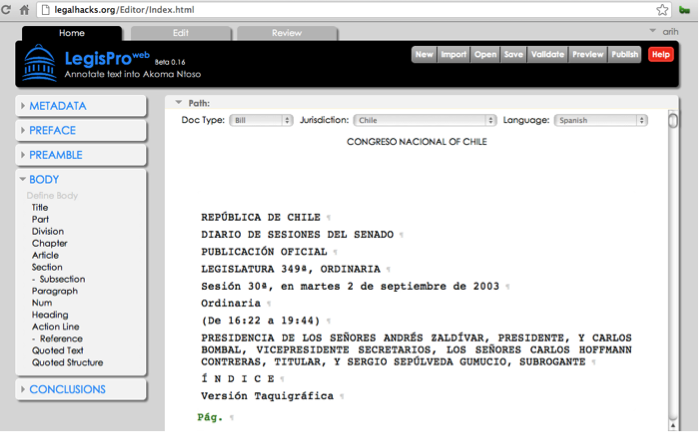
Legislative Editor at legalhacks.org
be a matter of time before all governments worldwide use such editors to draft their laws and regulations in a standard data format.
Advances in Legislative Data Standards Efforts
Akoma Ntoso
Akoma Ntoso (AkN) is a strong contender to be that format. Developed under the auspices of the UN Department of Economic and Social Affairs, AkN is an XML data structure that is meant to capture high-level forms and semantic ideas that are common to a broad variety of legal texts. OASIS, the folks who brought us the DocBook standards, among others, have convened a standards committee to create an official legislative data standard based on AkN. (More disclosure: the engineer is a member of this committee.) There’s just one problem. Few governments are using AkN to draft or store their legislation.
AkN itself is fast evolving, and with more exposure to legal data structures from different jurisdictions, the OASIS committee will be able to adapt AkN to better model those structures.
We saw the International Legislative Un-Hackathon as a venue to kick off this process. It was conceived with Charles Belle of UC Hastings, as part of the Legal Hacks initiative. The event was held simultaneously at UC Hastings, Stanford, in Denver. Jim Harper and Francis Avila of the Cato Institute came to the Hastings Event. We also had many international participants. Key among them were Professors Monica Palmirani and Fabio Vitali of the University of Bologna, the architects and primary evangelists of AkN. Over the course of the day, participants learned about AkN and, importantly, got a chance to try it out, marking up documents of their choosing with the web editor. In the process, as expected, we found bugs in the software and bugs in the standard. We found structures in U.S. legislation that didn’t fit well with the existing AkN element set. We saw places where there was confusion in applying AkN’s data structures to documents. All of this information was collected to incorporate in the development of both the editor and AkN, underscoring again the importance of getting more practical exposure for both.
University of Bologna Summer School–Ravenna
And we are working to expand the venues for this kind of practical exposure to develop the AkN standard. Every September, the University of Bologna hosts the LEX Summer School in Ravenna, Italy. For them, it’s an opportunity to introduce Akoma Ntoso to new groups of students from around Europe and around the world. For the students, it’s an opportunity to learn about the application of XML to legislation, see the success various groups are having around the world, and to meet interesting new people having a passion for legal informatics. One of us, the engineer, who was a student two years ago, was invited to return last year to present a success story, and this year is returning once more to deliver a class in how to build and use the HTML5-based editor for drafting legislation in XML. For us, this is an opportunity to expose the editor to the European legal traditions in order for us to better understand how our editor must evolve to fulfill our vision of a unified standard around the world with common, highly adaptable, tools.
Chile National Library of Congress Browser-based editor
Another step toward adoption of legislative data standards is a project by Chile’s National Library of Congress (BCN in Spanish) called the “History of the Law” (Historia de la Ley). This ambitious project aims to bring together machine learning, a legislative editor and other features to mark up Chile’s legislative record and other legislative documents. The BCN has chosen Xcential’s browser-based editor, working with the AkN standard, to conduct the mark-up and correction after documents are passed through an automated parser. As with the hackathon, but on a larger scale, we are learning from experience the modifications that are needed to AkN, to make it work with Chile’s live documents. Excitingly, each mismatch we find between AkN and actual legislation can be fed back into the OASIS committee process, to make AkN able to handle a wider variety of real-world use cases.
Other Efforts and the Future of Legislative Data Standards
We see these steps as just the beginning. European governments are also flirting with legislative standards, and Karen Suhaka’s group at BillTrack50 has converted all U.S. bills from all states into a single standard XML format showing that the technical hurdles can be overcome, and many of the practical benefits of doing so. In focusing on the projects (and hackathons) we are most closely involved with, we have certainly left out a lot of the initiatives that are advancing legislative data standards around the world. That’s what the comments are for. Let us know your experience with Akoma Ntosa as a legislative standard, and what you’re doing or interested in doing with AkN or other legislative data standards worldwide.
 Grant Vergottini (the engineer) is a founder of Xcential. He is a leading authority on applications of XML data to legislation. Prior to founding Xcential, Grant was the Director of Applications at Chrystal Software, a company dedicated to XML design and reporting software. Before Chrystal, Grant led the redesign of Homestore.com, and founded Genedax Design Automation, which developed innovative team and data management applications for electronics design. Bringing data structures and automation tools to the legislative drafting process parallels the work that Grant did earlier in his career at Mentor Graphics and the Boeing Company, where he participated in the transformation from manual drafting to CAD software. Mr. Vergottini holds a Bachelor of Science in Electrical Engineering from Cleveland State University, where he graduated Summa Cum Laude.
Grant Vergottini (the engineer) is a founder of Xcential. He is a leading authority on applications of XML data to legislation. Prior to founding Xcential, Grant was the Director of Applications at Chrystal Software, a company dedicated to XML design and reporting software. Before Chrystal, Grant led the redesign of Homestore.com, and founded Genedax Design Automation, which developed innovative team and data management applications for electronics design. Bringing data structures and automation tools to the legislative drafting process parallels the work that Grant did earlier in his career at Mentor Graphics and the Boeing Company, where he participated in the transformation from manual drafting to CAD software. Mr. Vergottini holds a Bachelor of Science in Electrical Engineering from Cleveland State University, where he graduated Summa Cum Laude.
 Ari Hershowitz (the lawyer) is a consultant at Xcential, and founder of Tabulaw. Tabulaw develops software for lawyers, including a web-based legal research and writing platform. Prior to Tabulaw, Ari worked to protect wildlife and habitats from Chile to Mexico as Director of the BioGems project for Latin America at the Natural Resources Defense Council. Ari has a law degree from Georgetown University Law Center, a Masters in Computation and Neural Systems from Caltech, and a Bachelors in Molecular Biophysics & Biochemistry from Yale College.
Ari Hershowitz (the lawyer) is a consultant at Xcential, and founder of Tabulaw. Tabulaw develops software for lawyers, including a web-based legal research and writing platform. Prior to Tabulaw, Ari worked to protect wildlife and habitats from Chile to Mexico as Director of the BioGems project for Latin America at the Natural Resources Defense Council. Ari has a law degree from Georgetown University Law Center, a Masters in Computation and Neural Systems from Caltech, and a Bachelors in Molecular Biophysics & Biochemistry from Yale College.
VoxPopuLII is edited by Judith Pratt. Editors-in-Chief are Stephanie Davidson and Christine Kirchberger, to whom queries should be directed.
[Editor’s Note: For topic-related VoxPopuLII posts please see: Núria Casellas, Semantic Enhancement of legal information … Are we up for the challenge?; João Lima, et.al, LexML Brazil Project; and Rinke Hoekstra, The MetaLex Document Server
THE JUDICIAL CONTEXT: WHY INNOVATE?
The progressive deployment of information and communication technologies (ICT) in the courtroom (audio and video recording, document scanning, courtroom management systems), jointly with the requirement for paperless judicial folders pushed by e-justice plans (Council of the European Union, 2009), are quickly transforming the traditional judicial folder into an integrated multimedia folder, where documents, audio recordings and video recordings can be accessed, usually via a Web-based platform. This trend is leading to a continuous increase in the number and the volume of case-related digital judicial libraries, where the full content of each single hearing is available for online consultation. A typical trial folder contains: audio hearing recordings, audio/video hearing recordings, transcriptions of hearing recordings, hearing reports, and attached documents (scanned text documents, photos, evidences, etc.). The ICT container is typically a dedicated judicial content management system (court management system), usually physically separated and independent from the case management system used in the investigative phase, but interacting with it.
Most of the present ICT deployment has been focused on the deployment of case management systems and ICT equipment in the courtrooms, with content management systems at different organisational levels (court or district). ICT deployment in the judiciary has reached different levels in the various EU countries, but the trend toward full e-justice is clearly in progress. Accessibility of the judicial information, both of case registries (more widely deployed), and of case e-folders, has been strongly enhanced by state-of-the-art ICT technologies. Usability of the electronic judicial folders is still affected by a traditional support toolset, such that an information search is limited to text search, transcription of audio recordings (indispensable for text search) is still a slow and fully manual process, template filling is a manual activity, etc. Part of the information available in the trial folder is not yet directly usable, but requires a time-consuming manual search. Information embedded in audio and video recordings, describing not only what was said in the courtroom, but also the specific trial context and the way in which it was said, still needs to be exploited. While the information is there, information extraction and semantically empowered judicial information retrieval still wait for proper exploitation tools. The growing amount of digital judicial information calls for the development of novel knowledge management techniques and their integration into case and court management systems. In this challenging context a novel case and court management system has been recently proposed.
the deployment of case management systems and ICT equipment in the courtrooms, with content management systems at different organisational levels (court or district). ICT deployment in the judiciary has reached different levels in the various EU countries, but the trend toward full e-justice is clearly in progress. Accessibility of the judicial information, both of case registries (more widely deployed), and of case e-folders, has been strongly enhanced by state-of-the-art ICT technologies. Usability of the electronic judicial folders is still affected by a traditional support toolset, such that an information search is limited to text search, transcription of audio recordings (indispensable for text search) is still a slow and fully manual process, template filling is a manual activity, etc. Part of the information available in the trial folder is not yet directly usable, but requires a time-consuming manual search. Information embedded in audio and video recordings, describing not only what was said in the courtroom, but also the specific trial context and the way in which it was said, still needs to be exploited. While the information is there, information extraction and semantically empowered judicial information retrieval still wait for proper exploitation tools. The growing amount of digital judicial information calls for the development of novel knowledge management techniques and their integration into case and court management systems. In this challenging context a novel case and court management system has been recently proposed.
The JUMAS project (JUdicial MAnagement by digital libraries Semantics) was started in February 2008, with the support of the Polish and Italian Ministries of Justice. JUMAS seeks to realize better usability of multimedia judicial folders — including transcriptions, information extraction, and semantic search –to provide to users a powerful toolset able to fully address the knowledge embedded in the multimedia judicial folder.
The JUMAS project has several objectives:
- (1) direct searching of audio and video sources without a verbatim transcription of the proceedings;
- (2) exploitation of the hidden semantics in audiovisual digital libraries in order to facilitate search and retrieval, intelligent processing, and effective presentation of multimedia information;
- (3) fusing information from multimodal sources in order to improve accuracy during the automatic transcription and the annotation phases;
- (4) optimizing the document workflow to allow the analysis of (un)structured information for document search and evidence-based assessment; and
- (5) supporting a large scale, scalable, and interoperable audio/video retrieval system.
JUMAS is currently under validation in the Court of Wroclaw (Poland) and in the Court of Naples (Italy).
THE DIMENSIONS OF THE PROBLEM
 In order to explain the relevance of the JUMAS objectives, we report some volume data related to the judicial domain context. Consider, for instance, the Italian context, where there are 167 courts, grouped in 29 districts, with about 1400 courtrooms. In a law court of medium size (10 courtrooms), during a single legal year, about 150 hearings per court are held, with an average duration of 4 hours. Considering that in approximately 40% of them only audio is recorded, in 20% both audio and video, while the remaining 40% has no recording, the multimedia recording volume we are talking about is 2400 hours of audio and 1200 hours of audio/video per year. The dimensioning related to the audio and audio/video documentation starts from the hypothesis that multimedia sources must be acquired at high quality in order to obtain good results in audio transcription and video annotation, which will affect the performance connected to the retrieval functionalities. Following these requirements, one can figure out a storage space of about 8.7 megabytes per minute (MB/min) for audio and 39 MB/min for audio/video. This means that during a legal year for a court of medium size we need to allocate 4 terabytes (TB) for audio/video material. Under these hypotheses, the overall size generated by all the courts in the justice system — for Italy only — in one year is about 800 TB. This shows how the justice sector is a major contributor to the data deluge (The Economist, 2010).
In order to explain the relevance of the JUMAS objectives, we report some volume data related to the judicial domain context. Consider, for instance, the Italian context, where there are 167 courts, grouped in 29 districts, with about 1400 courtrooms. In a law court of medium size (10 courtrooms), during a single legal year, about 150 hearings per court are held, with an average duration of 4 hours. Considering that in approximately 40% of them only audio is recorded, in 20% both audio and video, while the remaining 40% has no recording, the multimedia recording volume we are talking about is 2400 hours of audio and 1200 hours of audio/video per year. The dimensioning related to the audio and audio/video documentation starts from the hypothesis that multimedia sources must be acquired at high quality in order to obtain good results in audio transcription and video annotation, which will affect the performance connected to the retrieval functionalities. Following these requirements, one can figure out a storage space of about 8.7 megabytes per minute (MB/min) for audio and 39 MB/min for audio/video. This means that during a legal year for a court of medium size we need to allocate 4 terabytes (TB) for audio/video material. Under these hypotheses, the overall size generated by all the courts in the justice system — for Italy only — in one year is about 800 TB. This shows how the justice sector is a major contributor to the data deluge (The Economist, 2010).
In order to manage such quantities of complex data, JUMAS aims to:
- Optimize the workflow of information through search, consultation, and archiving procedures;
- Introduce a higher degree of knowledge through the aggregation of different heterogeneous sources;
- Speed up and improve decision processes by enabling discovery and exploitation of knowledge embedded in multimedia documents, in order to consequently reduce unnecessary costs;
- Model audio-video proceedings in order to compare different instances; and
- Allow traceability of proceedings during their evolution.
THE JUMAS SYSTEM
To achieve the above-mentioned goals, the JUMAS project has delivered the JUMAS system, whose main functionalities (depicted in Figure 1) are: automatic speech transcription, emotion recognition, human behaviour annotation, scene analysis, multimedia summarization, template-filling, and deception recognition.
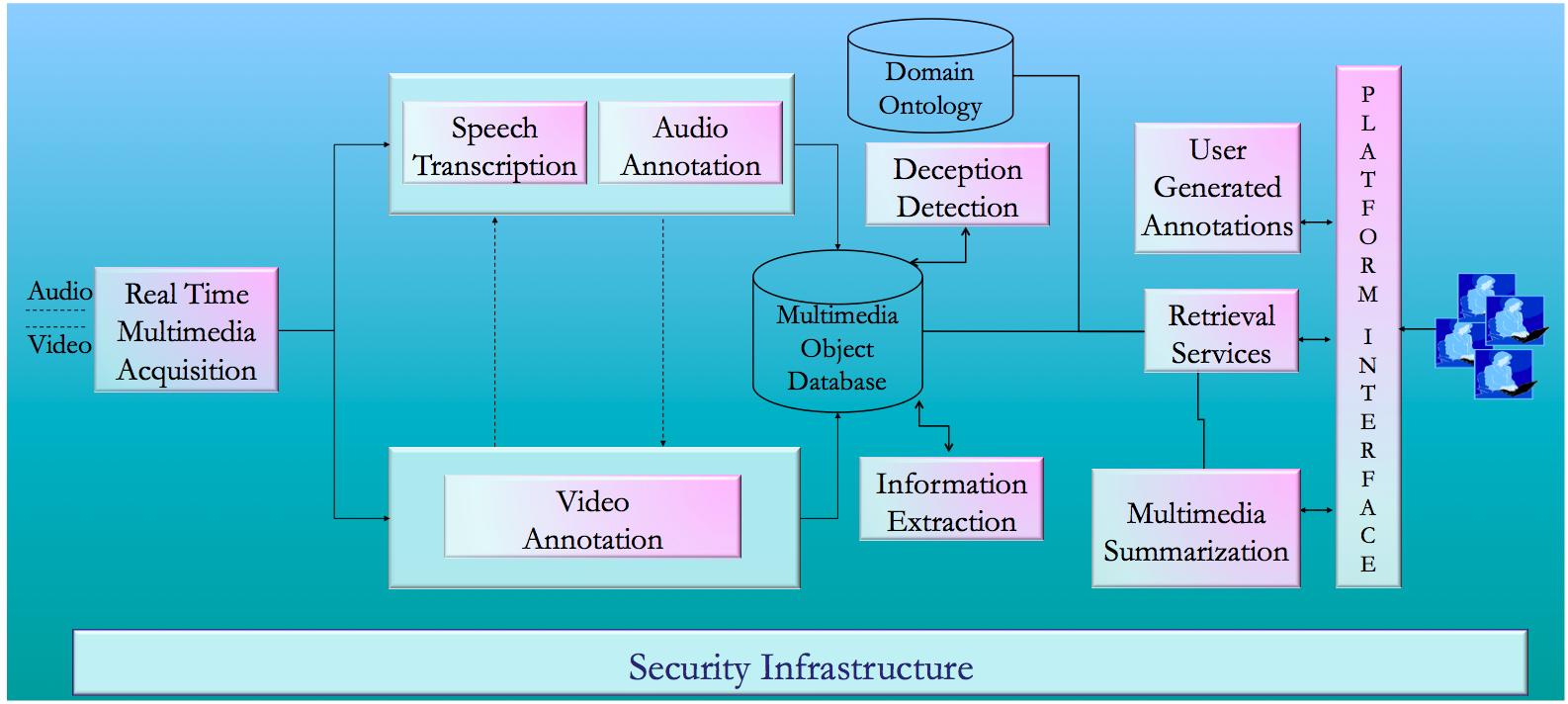
Figure 1: Overview of the JUMAS functionalities
The architecture of JUMAS, depicted in Figure 2, is based on a set of key components: a central database, a user interface on a Web portal, a set of media analysis modules, and an orchestration module that allows the coordination of all system functionalities.
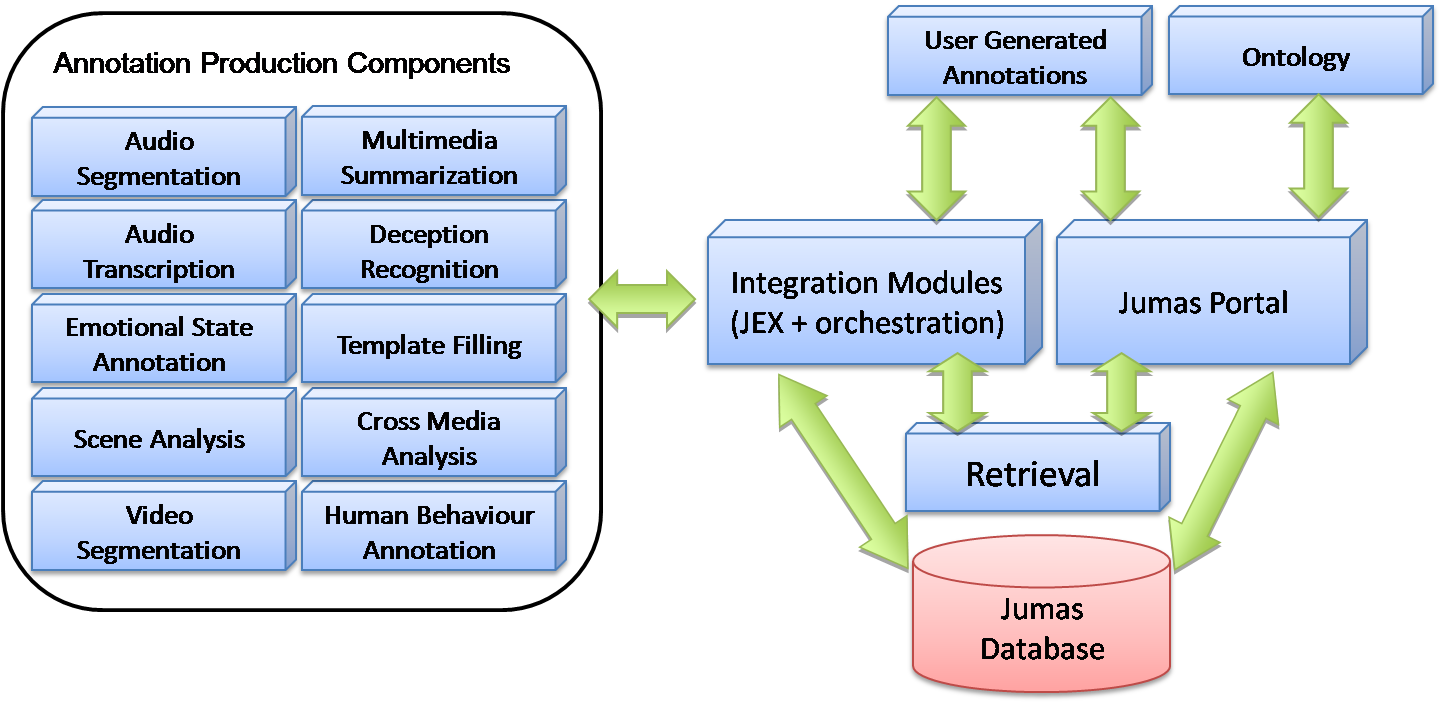
Figure 2: Overview of the JUMAS architecture
The media stream recorded in the courtroom includes both audio and video that are analyzed to extract semantic information used to populate the multimedia object database. The outputs of these processes are annotations: i.e., tags attached to media streams and stored in the database (Oracle 11g). The integration among modules is performed through a workflow engine and a module called JEX (JUMAS EXchange library). While the workflow engine is a service application that manages all the modules for audio and video analysis, JEX provides a set of services to upload and retrieve annotations to and from the JUMAS database.
JUMAS: THE ICT COMPONENTS
KNOWLEDGE EXTRACTION
![]() Automatic Speech Transcription. For courtroom users, the primary sources of information are audio-recordings of hearings/proceedings. In light of this, JUMAS provides an Automatic Speech Recognition (ASR) system (Falavigna et al., 2009 and Rybach et al., 2009) trained on real judicial data coming from courtrooms. Currently two ASR systems have been developed: the first provided by Fondazione Bruno Kessler for the Italian language, and the second delivered by RWTH Aachen University for the Polish language. Currently, the ASR modules in the JUMAS system offer 61% accuracy over the generated automatic transcriptions, and represent the first contribution for populating the digital libraries with judicial trial information. In fact, the resulting transcriptions are the main information resource that are to be enriched by other modules, and then can be consulted by end users through the information retrieval system.
Automatic Speech Transcription. For courtroom users, the primary sources of information are audio-recordings of hearings/proceedings. In light of this, JUMAS provides an Automatic Speech Recognition (ASR) system (Falavigna et al., 2009 and Rybach et al., 2009) trained on real judicial data coming from courtrooms. Currently two ASR systems have been developed: the first provided by Fondazione Bruno Kessler for the Italian language, and the second delivered by RWTH Aachen University for the Polish language. Currently, the ASR modules in the JUMAS system offer 61% accuracy over the generated automatic transcriptions, and represent the first contribution for populating the digital libraries with judicial trial information. In fact, the resulting transcriptions are the main information resource that are to be enriched by other modules, and then can be consulted by end users through the information retrieval system.
 Emotion Recognition. Emotional states represent an aspect of knowledge embedded into courtroom media streams that may be used to enrich the content available in multimedia digital libraries. Enabling the end user to consult transcriptions by considering the associated semantics as well, represents an important achievement, one that allows the end user to retrieve an enriched written sentence instead of a “flat” one. Even if there is an open ethical discussion about the usability of this kind of information, this achievement radically changes the consultation process: sentences can assume different meanings according to the affective state of the speaker. To this purpose an emotion recognition module (Archetti et al., 2008), developed by the Consorzio Milano Ricerche jointly with the University of Milano-Bicocca, is part of the JUMAS system. A set of real-world human emotions obtained from courtroom audio recordings has been gathered for training the underlying supervised learning model.
Emotion Recognition. Emotional states represent an aspect of knowledge embedded into courtroom media streams that may be used to enrich the content available in multimedia digital libraries. Enabling the end user to consult transcriptions by considering the associated semantics as well, represents an important achievement, one that allows the end user to retrieve an enriched written sentence instead of a “flat” one. Even if there is an open ethical discussion about the usability of this kind of information, this achievement radically changes the consultation process: sentences can assume different meanings according to the affective state of the speaker. To this purpose an emotion recognition module (Archetti et al., 2008), developed by the Consorzio Milano Ricerche jointly with the University of Milano-Bicocca, is part of the JUMAS system. A set of real-world human emotions obtained from courtroom audio recordings has been gathered for training the underlying supervised learning model.
 Human Behavior Annotation. A further fundamental information resource is related to the video stream. In addition to emotional states identification, the recognition of relevant events that characterize judicial proceedings can be valuable for end users. Relevant events occurring during proceedings trigger meaningful gestures, which emphasize and anchor the words of witnesses, and highlight that a relevant concept has been explained. For this reason, the human behavior recognition modules (Briassouli et al., 2009, Kovacs et al., 2009), developed by CERTH-ITI and by MTA SZTAKI Research Institute, have been included in the JUMAS system. The video analysis captures relevant events that occur during the course of a trial in order to create semantic annotations that can be retrieved by judicial end users. The annotations are mainly concerned with the events related to the witness: change of posture, change of witness, hand gestures, gestures indicating conflict or disagreement.
Human Behavior Annotation. A further fundamental information resource is related to the video stream. In addition to emotional states identification, the recognition of relevant events that characterize judicial proceedings can be valuable for end users. Relevant events occurring during proceedings trigger meaningful gestures, which emphasize and anchor the words of witnesses, and highlight that a relevant concept has been explained. For this reason, the human behavior recognition modules (Briassouli et al., 2009, Kovacs et al., 2009), developed by CERTH-ITI and by MTA SZTAKI Research Institute, have been included in the JUMAS system. The video analysis captures relevant events that occur during the course of a trial in order to create semantic annotations that can be retrieved by judicial end users. The annotations are mainly concerned with the events related to the witness: change of posture, change of witness, hand gestures, gestures indicating conflict or disagreement.
 Deception Detection. Discriminating between truthful and deceptive assertions is one of the most important activities performed by judges, lawyers, and prosecutors. In order to support these individuals’ reasoning activities, respecting corroborating/contradicting declarations (in the case of lawyers and prosecutors) and judging the accused (judges), a deception recognition module has been developed as a support tool. The deception detection module developed by the Heidelberg Institute for Theoretical Studies is based on the automatic classification of sentences performed by the ASR systems (Ganter and Strube, 2009). In particular, in order to train the deception detection module, a manual annotation of the output of the ASR module — with the help of the minutes of the transcribed sessions — has been performed. The knowledge extracted for training the classification module deals with lies, contradictory statements, quotations, and expressions of vagueness.
Deception Detection. Discriminating between truthful and deceptive assertions is one of the most important activities performed by judges, lawyers, and prosecutors. In order to support these individuals’ reasoning activities, respecting corroborating/contradicting declarations (in the case of lawyers and prosecutors) and judging the accused (judges), a deception recognition module has been developed as a support tool. The deception detection module developed by the Heidelberg Institute for Theoretical Studies is based on the automatic classification of sentences performed by the ASR systems (Ganter and Strube, 2009). In particular, in order to train the deception detection module, a manual annotation of the output of the ASR module — with the help of the minutes of the transcribed sessions — has been performed. The knowledge extracted for training the classification module deals with lies, contradictory statements, quotations, and expressions of vagueness.
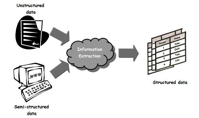 Information Extraction. The current amount of unstructured textual data available in the judicial domain, especially related to transcriptions of proceedings, highlights the necessity of automatically extracting structured data from unstructured material, to facilitate efficient consultation processes. In order to address the problem of structuring data coming from the automatic speech transcription system, Consorzio Milano Ricerche has defined an environment that combines regular expressions, probabilistic models, and background information available in each court database system. Thanks to this functionality, the judicial actors can view each individual hearing as a structured summary, where the main information extracted consists of the names of the judge, lawyers, defendant, victim, and witnesses; the names of the subjects cited during a deposition; the date cited during a deposition; and data about the verdict.
Information Extraction. The current amount of unstructured textual data available in the judicial domain, especially related to transcriptions of proceedings, highlights the necessity of automatically extracting structured data from unstructured material, to facilitate efficient consultation processes. In order to address the problem of structuring data coming from the automatic speech transcription system, Consorzio Milano Ricerche has defined an environment that combines regular expressions, probabilistic models, and background information available in each court database system. Thanks to this functionality, the judicial actors can view each individual hearing as a structured summary, where the main information extracted consists of the names of the judge, lawyers, defendant, victim, and witnesses; the names of the subjects cited during a deposition; the date cited during a deposition; and data about the verdict.
KNOWLEDGE MANAGEMENT
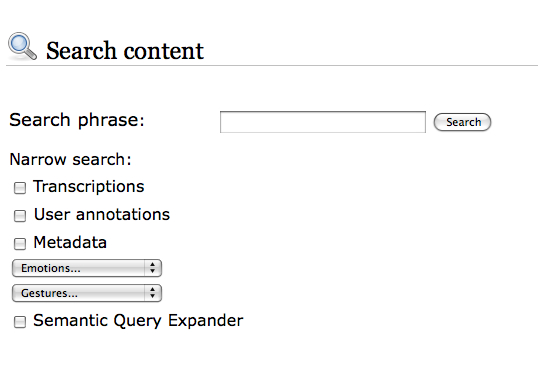 Information Retrieval. Currently, to retrieve audio/video materials acquired during a trial, the end user must manually consult all of the multimedia tracks. The identification of a particular position or segment of a multimedia stream, for purposes of looking at and/or listening to specific declarations, is possible either by remembering the time stamp when the events occurred, or by watching or hearing the whole recording. The amalgamation of automatic transcriptions, semantic annotations, and ontology representations allows us to build a flexible retrieval environment, based not only on simple textual queries, but also on broad and complex concepts. In order to define an integrated platform for cross-modal access to audio and video recordings and their automatic transcriptions, a retrieval module able to perform semantic multimedia indexing and retrieval has been developed by the Information Retrieval group at MTA SZTAKI. (Darczy et al., 2009)
Information Retrieval. Currently, to retrieve audio/video materials acquired during a trial, the end user must manually consult all of the multimedia tracks. The identification of a particular position or segment of a multimedia stream, for purposes of looking at and/or listening to specific declarations, is possible either by remembering the time stamp when the events occurred, or by watching or hearing the whole recording. The amalgamation of automatic transcriptions, semantic annotations, and ontology representations allows us to build a flexible retrieval environment, based not only on simple textual queries, but also on broad and complex concepts. In order to define an integrated platform for cross-modal access to audio and video recordings and their automatic transcriptions, a retrieval module able to perform semantic multimedia indexing and retrieval has been developed by the Information Retrieval group at MTA SZTAKI. (Darczy et al., 2009)
Ontology as Support to Information Retrieval. An ontology is a formal representation of the knowledge that characterizes a given domain, through a set of concepts and a set of relationships that obtain among them. In the judicial domain, an ontology represents a key element that supports the retrieval process performed by end users. Text-based retrieval functionalities are not sufficient for finding and consulting transcriptions (and other documents) related to a given trial. A first contribution of the ontology component developed by the University of Milano-Bicocca (CSAI Research Center) for the JUMAS system provides query expansion functionality. Query expansion aims at extending the original query specified by end users with additional related terms. The whole set of keywords is then automatically submitted to the retrieval engine. The main objective is to narrow the search focus or to increase recall.
User Generated Semantic Annotations. Judicial users usually manually tag some documents for purposes of highlighting (and then remembering) significant portions of the proceedings. An important functionality, developed by the European Media Laboratory and offered by the JUMAS system, relates to the possibility of digitally annotating relevant arguments discussed during a proceeding. In this context, the user-generated annotations may aid judicial users in future retrieval and reasoning processes. The user-generated annotations module included in the JUMAS system allows end users to assign free tags to multimedia content in order to organize the trials according to their personal preferences. It also enables judges, prosecutors, lawyers, and court clerks to work collaboratively on a trial; e.g., a prosecutor who is taking over a trial can build on the notes of his or her predecessor.
KNOWLEDGE VISUALIZATION
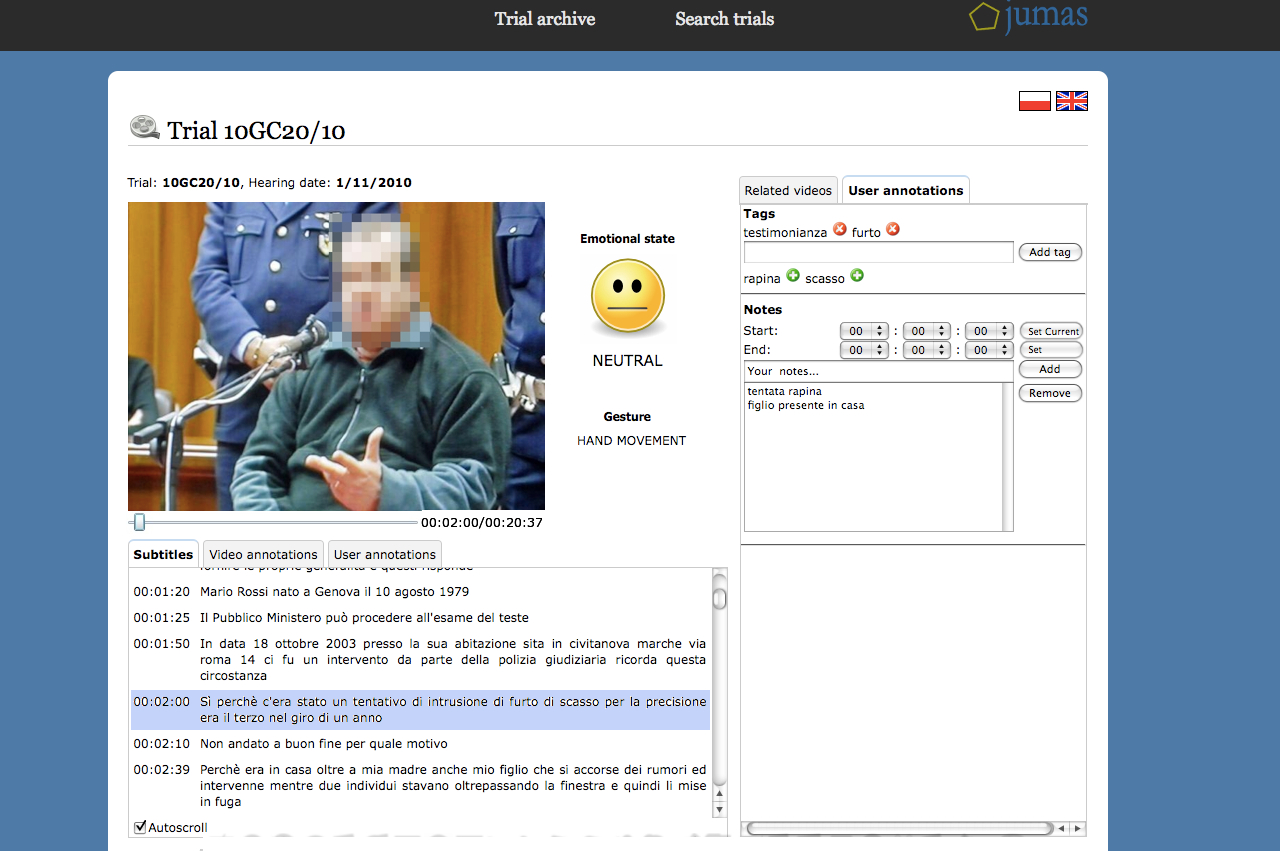 Hyper Proceeding Views. The user interface of JUMAS — developed by ESA Projekt and Consorzio Milano Ricerche — is a Web portal, in which the contents of the database are presented in different views. The basic view allows browsing of the trial archive, as in a typical court management system, to view general information (dates of hearings, name of people involved) and documents attached to each trial. JUMAS’s distinguishing features include the automatic creation of a summary of the trial, the presentation of user-generated annotations, and the Hyper Proceeding View: i.e., an advanced presentation of media contents and annotations that allows the user to perform queries on contents, and jump directly to relevant parts of media files.
Hyper Proceeding Views. The user interface of JUMAS — developed by ESA Projekt and Consorzio Milano Ricerche — is a Web portal, in which the contents of the database are presented in different views. The basic view allows browsing of the trial archive, as in a typical court management system, to view general information (dates of hearings, name of people involved) and documents attached to each trial. JUMAS’s distinguishing features include the automatic creation of a summary of the trial, the presentation of user-generated annotations, and the Hyper Proceeding View: i.e., an advanced presentation of media contents and annotations that allows the user to perform queries on contents, and jump directly to relevant parts of media files.
Multimedia Summarization. Digital videos represent a fundamental information resource about the events that occur during a trial: such videos can be stored, organized, and retrieved in a short time and at low cost. However, considering the dimensions that a video resource can assume during the recording of a trial, judicial actors have specified several requirements for digital trial videos: fast navigation of the stream, efficient access to data within the stream, and effective representation of relevant contents. One possible solution to these requirements lies in multimedia summarization, which derives a synthetic representation of audio/video contents with a minimal loss of meaningful information. In order to address the problem of defining a short and meaningful representation of a proceeding, a multimedia summarization environment based on an unsupervised learning approach has been developed (Fersini et al., 2010) by Consorzio Milano Ricerche jointly with University of Milano-Bicocca.
CONCLUSION
The JUMAS project demonstrates the feasibility of enriching a court management system with an advanced toolset for extracting and using the knowledge embedded in a multimedia judicial folder. Automatic transcription, template filling, and semantic enrichment help judicial actors not only to save time, but also to enhance the quality of their judicial decisions and performance. These improvements are mainly due to the ability to search not only text, but also events that occur in the courtroom. The initial results of the JUMAS project indicate that automatic transcription and audio/video annotations can provide additional information in an affordable way.

Elisabetta Fersini has a post-doctoral research fellow position at the University of Milano-Bicocca. She received her PhD with a thesis on “Probabilistic Classification and Clustering using Relational Models.” Her research interest is mainly focused on (Relational) Machine Learning in several domains, including Justice, Web, Multimedia, and Bioinformatics.
VoxPopuLII is edited by Judith Pratt.
Editor-in-Chief is Robert Richards, to whom queries should be directed.
 The World Wide Web is a virtual cornucopia of legal information bearing on all manner of topics and in a spectrum of formats, much of it textual. However, to make use of this storehouse of textual information, it must be annotated and structured in such a way as to be meaningful to people and processable by computers. One of the visions of the Semantic Web has been to enrich information on the Web with annotation and structure. Yet, given that text is in a natural language (e.g., English, German, Japanese, etc.), which people can understand but machines cannot, some automated processing of the text itself is needed before further processing can be applied. In this article, we discuss one approach to legal information on the World Wide Web, the Semantic Web, and Natural Language Processing (NLP). Each of these are large, complex, and heterogeneous topics of research; in this short post, we can only hope to touch on a fragment and that heavily biased to our interests and knowledge. Other important approaches are mentioned at the end of the post. We give small working examples of legal textual input, the Semantic Web output, and how NLP can be used to process the input into the output.
The World Wide Web is a virtual cornucopia of legal information bearing on all manner of topics and in a spectrum of formats, much of it textual. However, to make use of this storehouse of textual information, it must be annotated and structured in such a way as to be meaningful to people and processable by computers. One of the visions of the Semantic Web has been to enrich information on the Web with annotation and structure. Yet, given that text is in a natural language (e.g., English, German, Japanese, etc.), which people can understand but machines cannot, some automated processing of the text itself is needed before further processing can be applied. In this article, we discuss one approach to legal information on the World Wide Web, the Semantic Web, and Natural Language Processing (NLP). Each of these are large, complex, and heterogeneous topics of research; in this short post, we can only hope to touch on a fragment and that heavily biased to our interests and knowledge. Other important approaches are mentioned at the end of the post. We give small working examples of legal textual input, the Semantic Web output, and how NLP can be used to process the input into the output.
Legal Information on the Web
For clients, legal professionals, and public administrators, the Web provides an unprecedented opportunity to search for, find, and reason with legal information such as case law, legislation, legal opinions, journal articles, and material relevant to discovery in a court procedure. With a search tool such as Google or indexed searches made available by Lexis-Nexis, Westlaw, or the World Legal Information Institute, the legal researcher can input key words into a search and get in return a (usually long) list of documents which contain, or are indexed by, those key words.
As useful as such searches are, they are also highly limited to the particular words or indexation provided, for the legal researcher must still manually examine the documents to find the substantive information. Moreover, current legal search mechanisms do not support more meaningful searches such as for properties or relationships, where, for example, a legal researcher searches for cases in which a company has the property of being in the role of plaintiff or where a lawyer is in the relationship of representing a client. Nor, by the same token, can searches be made with respect to more general (or more specific) concepts, such as “all cases in which a company has any role,” some particular fact pattern, legislation bearing on related topics, or decisions on topics related to a legal subject.
 The underlying problem is that legal textual information is expressed in natural language. What literate people read as meaningful words and sentences appear to a computer as just strings of ones and zeros. Only by imposing some structure on the binary code is it converted to textual characters as we know them. Yet, there is no similar widespread system for converting the characters into higher levels of structure which correlate to our understanding of meaning. While a search can be made for the string plaintiff, there are no (widely available) searches for a string that represents an individual who bears the role of plaintiff. To make language on the Web more meaningful and structured, additional content must be added to the source material, which is where the Semantic Web and Natural Language Processing come into play.
The underlying problem is that legal textual information is expressed in natural language. What literate people read as meaningful words and sentences appear to a computer as just strings of ones and zeros. Only by imposing some structure on the binary code is it converted to textual characters as we know them. Yet, there is no similar widespread system for converting the characters into higher levels of structure which correlate to our understanding of meaning. While a search can be made for the string plaintiff, there are no (widely available) searches for a string that represents an individual who bears the role of plaintiff. To make language on the Web more meaningful and structured, additional content must be added to the source material, which is where the Semantic Web and Natural Language Processing come into play.
Semantic Web
The Semantic Web is a complex of design principles and technologies which are intended to make information on the Web more meaningful and usable to people.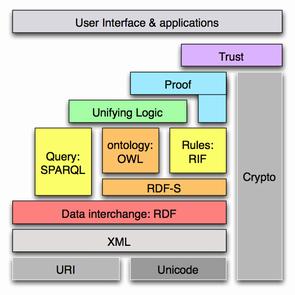 We focus on only a small portion of this structure, namely the syntactic XML (eXtensible Markup Language) level, where elements are annotated so as to indicate linguistically relevant information and structure. (Click here for more on these points.) While the XML level may be construed as a ‘lower’ level in the Semantic Web “stack” — i.e., the layers of interrelated technologies that make up the Semantic Web — the XML level is nonetheless crucial to providing information to higher levels where ontologies (and click here for more on this) and logic play a role. So as to be clear about the relation between the Semantic Web and NLP, we briefly review aspects of XML by example, and furnish motivations as we go.
We focus on only a small portion of this structure, namely the syntactic XML (eXtensible Markup Language) level, where elements are annotated so as to indicate linguistically relevant information and structure. (Click here for more on these points.) While the XML level may be construed as a ‘lower’ level in the Semantic Web “stack” — i.e., the layers of interrelated technologies that make up the Semantic Web — the XML level is nonetheless crucial to providing information to higher levels where ontologies (and click here for more on this) and logic play a role. So as to be clear about the relation between the Semantic Web and NLP, we briefly review aspects of XML by example, and furnish motivations as we go.
Suppose one looks up a case where Harris Hill is the plaintiff and Jane Smith is the attorney for Harris Hill. In a document related to this case, we would see text such as the following portions:
Harris Hill, plaintiff.
Jane Smith, attorney for the plaintiff.
While it is relatively straightforward to structure the binary string into characters, adding further information is more difficult. Consider what we know about this small fragment: Harris and Jane are (very likely) first names, Hill and Smith are last names, Harris Hill and Jane Smith are full names of people, plaintiff and attorney are roles in a legal case, Harris Hill has the role of plaintiff, attorney for is a relationship between two entities, and Jane Smith is in the attorney for relationship to Harris Hill. It would be useful to encode this information into a standardised machine-readable and processable form.
XML helps to encode the information by specifying requirements for tags that can be used to annotate the text. It is a highly expressive language, allowing one to define tags that suit one’s purposes so long as the specification requirements are met. One requirement is that each tag has a beginning and an ending; the material in between is the data that is being tagged. For example, suppose tags such as the following, where … indicates the data:
<legalcase>...</legalcase>,
<firstname>...</firstname>,
<lastname>...</lastname>,
<fullname>...</fullname>,
<plaintiff>...</plaintiff>,
<attorney>...</attorney>,
<legalrelationship>...</legalrelationship>
Another requirement is that the tags have a tree structure, where each pair of tags in the document is included in another pair of tags and there is no crossing over:
<fullname><firstname>...</firstname>,
<lastname>...</lastname></fullname>
is acceptable, but
<fullname><firstname>...<lastname>
</firstname> ...</lastname></fullname>
is unacceptable. Finally, XML tags can be organised into schemas to structure the tags.
With these points in mind, we could represent our fragment as:
<legalcase>
<legalrelationship>
<plaintiff>
<fullname><firstname>Harris</firstname>,
<lastname>Hill</lastname></fullname>
</plaintiff>,
<attorney>
<fullname><firstname>Jane</firstname>,
<lastname>Smith</lastname></fullname>
</attorney>
</legalrelationship
</legalcase>
We have added structured information — the tags — to the original text. While this is more difficult for us to read, it is very easy for a machine to read and process. In addition, the tagged text contains the content of the information, which can be presented in a range of alternative ways and formats using a transformation language such as XSLT (click here for more on this point) so that we have an easier-to-read format.
Why bother to include all this additional information in a legal text? Because these additions allow us to query the source text and submit the information to further processing such as inference. Given a query language, we could submit to the machine the query Who is the attorney in the case? and the answer would be Jane Smith. Given a rule language — such as RuleML or Semantic Web Rule Language (SWRL) — which has a rule such as If someone is an attorney for a client then that client has a privileged relationship with the attorney, it might follow from this rule that the attorney could not divulge the client’s secrets. Applying such a rule to our sample, we could infer that Jane Smith cannot divulge Harris Hill’s secrets.
 Though it may seem here like too much technology for such a small and obvious task, it is essential where we scale up our queries and inferences on large corpora of legal texts — hundreds of thousands if not millions of documents — which comprise vast storehouses of unstructured, yet meaningful data. Were all legal cases uniformly annotated, we could, in principle, find out every attorney for every plaintiff for every legal case. Where our tagging structure is very rich, our queries and inferences could also be very rich and detailed. Perhaps a more familiar way to view documents annotated with XML is as a database to which further processes can be applied over the Web.
Though it may seem here like too much technology for such a small and obvious task, it is essential where we scale up our queries and inferences on large corpora of legal texts — hundreds of thousands if not millions of documents — which comprise vast storehouses of unstructured, yet meaningful data. Were all legal cases uniformly annotated, we could, in principle, find out every attorney for every plaintiff for every legal case. Where our tagging structure is very rich, our queries and inferences could also be very rich and detailed. Perhaps a more familiar way to view documents annotated with XML is as a database to which further processes can be applied over the Web.
Natural Language Processing
As we have presented it, we have an input, the corpus of texts, and an output, texts annotated with XML tags. The objective is to support a range of processes such as querying and inference. However, getting from a corpus of textual information to annotated output is a demanding task, generically referred to as the knowledge acquisition bottleneck. Not only is the task demanding on resources (time, money, manpower); it is also highly knowledge intensive since whoever is doing the annotation must know what to look for, and it is important that all of the annotators annotate the text in the same way (inter-annotator agreement) to support the processes. Thus, automation is central.
Yet processing language to support such richly annotated documents confronts a spectrum of difficult issues. Among them, natural language supports (1) implicit or presupposed information, (2) multiple forms with the same meaning, (3) the same form with different contextually dependent meanings, and (4) dispersed meanings. (Similar points can be made for sentences or other linguistic elements.) Here are examples of these four issues:
(1) “When did you stop taking drugs?” (presupposes that the person being questioned took drugs at sometime in the past);
(2) Jane Smith, Jane R. Smith, Smith, Attorney Smith… (different ways to refer to the same person);
(3) The individual referred to by the name “Jane Smith” in one case decision may not be the individual referred to by the name “Jane Smith” in another case decision;
(4) Jane Smith represented Jones Inc. She works for Dewey, Cheetum, and Howe. To contact her, write to j.smith@dch.com .
When we search for information, a range of linguistic structures or relationships may be relevant to our query, such as:
- grammatical constructions (passive or active sentence forms, quotation, reference to other individuals, and so on),
- grammatical relations among terms (e.g., whether an individual is the agent or target of some action),
- ontological relations (e.g., classes and subclasses of experts, or the relationships among courts in the judicial hierarchy),
- relationships among elements (e.g., who works for what organization), or
- high-level patterns such as legal arguments (e.g., expert testimony) and fact patterns (e.g., culpable intent).
People grasp relationships between words and phrases, such that Bill exercises daily contrasts with the meaning of Bill is a couch potato, or that if it is true that Bill used a knife to kill Phil, then Bill killed Phil. Finally, meaning tends to be sparse; that is, there are a few words and patterns that occur very regularly, while most words or patterns occur relatively rarely in the corpus.
Natural language processing (NLP) takes on this highly complex and daunting problem as an engineering problem, decomposing large problems into smaller problems and subdomains until it gets to those which it can begin to address. Having found a solution to smaller problems, NLP can then address other problems or larger scope problems. Some of the subtopics in NLP are:
- Generation – converting information in a database into natural language.
- Understanding – converting natural language into a machine-readable form.
- Information Retrieval – gathering documents which contain key words or phrases. This is essentially what is done by Google.
- Text Summarization – summarizing (in a paragraph) the main meaning of a text or corpus.
- Question Answering – making queries and giving answers to them, in natural language, with respect to some corpus of texts.
- Information Extraction — identifying, annotating, and extracting information from documents for reuse, representation, or reasoning.
In this article, we are primarily (here) interested in information extraction.
NLP Approaches: Knowledge Light v. Knowledge Heavy
There are a range of techniques that one can apply to analyse the linguistic data obtained from legal texts; each of these techniques has strengths and weaknesses with respect to different problems. Statistical and machine-learning techniques are considered “knowledge light.” With statistical approaches, the processing presumes very little knowledge by the system (or analyst). Rather, algorithms are applied that compare and contrast large bodies of textual data, and identify regularities and similarities. Such algorithms encounter problems with sparse data or patterns that are widely dispersed across the text. (See Turney and Pantel (2010) for an overview of this area.) Machine learning approaches apply learning algorithms to annotated material to extend results to unannotated material, thus introducing more knowledge into the processing pipeline. However, the results are somewhat of a black box in that we cannot really know the rules that are learned and use them further.
With a “knowledge-heavy” approach, we know, in a sense, what we are looking for, and make this knowledge explicit in lists and rules for processing. Yet, this is labour- and knowledge-intensive. In the legal domain it is crucial to have humanly understandable explanations and justifications for the analysis of a text, which to our thinking warrants a knowledge-heavy approach.
One open source text-mining package, General Architecture for Text Engineering (GATE), consists of multiple components in a cascade or pipeline, each component automatically processing some aspect of the text, and then feeding into the next process. The underlying strategy in all the components is to find a pattern (from either a list or a previous process) which matches a rule, and then to apply the rule which annotates the text. Each component performs a particular process on the text, such as:
- Sentence segmentation – dividing text into sentences.
- Tokenisation – words identified by spaces between them.
- Part-of-speech tagging – noun, verb, adjective, etc., determined by look-up and relationships among words.
- Shallow syntactic parsing/chunking – dividing the text by noun phrase, verb phrase, subordinate clause, etc.
- Named entity recognition – the entities in the text such as organisations, people, and places.
- Dependency analysis – subordinate clauses, pronominal anaphora [i.e., identifying what a pronoun refers to], etc.
The system can also be used to annotate more specifically to elements of interest. In one study, we annotated legal cases from a case base (a corpus of cases) in order to identify a range of particular pieces of information that would be relevant to legal professionals such as:
- Case citation.
- Names of parties.
- Roles of parties, meaning plaintiff or defendant.
- Type of court.
- Names of judges.
- Names of attorneys.
- Roles of attorneys, meaning the side they represent.
- Final decision.
- Cases cited.
- Nature of the case, meaning using keywords to classify the case in terms of subject (e.g., criminal assault, intellectual property, etc.)
Applying our lists and rules to a corpus of legal cases, a sample output is as follows, where the coloured highlights are annotated as per the key on the right; the colours are a visualisation of the sorts of tags discussed above (to see a larger version of the image, right click on the image, then click on “View Image” or a similar phrase; when finished viewing the image, use the browser’s back button to return to the text):

The approach is very flexible and appears in similar systems. (See, for example, de Maat and Winkels, Automatic Classification of Sentences in Dutch Laws (2008).) While it is labour intensive to develop and maintain such list and rule systems, with a collaborative, Web-based approach, it may be feasible to construct rich systems to annotate large domains.
Conclusion
In this post, we have given a very brief overview of how the Semantic Web and Natural Language Processing (NLP) apply to legal textual information to support annotation which then enables querying and inference. Of course, this is but one take on a much larger domain. In our view, it holds great promise in making legal information more transparent and available to more legal professionals. Aside from GATE, some other resources on text analytics and NLP are textbooks and lecture notes (see, e.g., Wilcock), as well as workshops (such as SPLeT and LOAIT). While applications of Natural Language Processing to legal materials are largely lab studies, the use of NLP in conjunction with Semantic Web technology to annotate legal texts is a fast-developing, results-oriented area which targets meaningful applications for legal professionals. It is well worth watching.
 Dr. Adam Zachary Wyner is a Research Fellow at the University of Leeds, Institute of Communication Studies, Centre for Digital Citizenship. He currently works on the EU-funded project IMPACT: Integrated Method for Policy Making Using Argument Modelling and Computer Assisted Text Analysis. Dr. Wyner has a Ph.D. in Linguistics (Cornell, 1994) and a Ph.D. in Computer Science (King’s College London, 2008). His computer science Ph.D. dissertation is entitled Violations and Fulfillments in the Formal Representation of Contracts. He has published in the syntax and semantics of adverbs, deontic logic, legal ontologies, and argumentation theory with special reference to law. He is workshop co-chair of SPLeT 2010: Workshop on Semantic Processing of Legal Texts, to be held 23 May 2010 in Malta. He writes about his research at his blog, Language, Logic, Law, Software.
Dr. Adam Zachary Wyner is a Research Fellow at the University of Leeds, Institute of Communication Studies, Centre for Digital Citizenship. He currently works on the EU-funded project IMPACT: Integrated Method for Policy Making Using Argument Modelling and Computer Assisted Text Analysis. Dr. Wyner has a Ph.D. in Linguistics (Cornell, 1994) and a Ph.D. in Computer Science (King’s College London, 2008). His computer science Ph.D. dissertation is entitled Violations and Fulfillments in the Formal Representation of Contracts. He has published in the syntax and semantics of adverbs, deontic logic, legal ontologies, and argumentation theory with special reference to law. He is workshop co-chair of SPLeT 2010: Workshop on Semantic Processing of Legal Texts, to be held 23 May 2010 in Malta. He writes about his research at his blog, Language, Logic, Law, Software.
VoxPopuLII is edited by Judith Pratt. Editor in chief is Robert Richards.