



VoxPopuLII
 This post is divided into three topical sections. The first one is an introduction to the LexML Brazil Project and its unified search portal, after which some aspects related to semantic interoperability shall be presented and, at the end, we show the current work and future direction of the project.
This post is divided into three topical sections. The first one is an introduction to the LexML Brazil Project and its unified search portal, after which some aspects related to semantic interoperability shall be presented and, at the end, we show the current work and future direction of the project.
Before going on to the aforementioned subjects, a few words about Brazil and its legislative and legal systems are necessary. Brazil is a country of continental proportions, composed of 27 states and more than five thousand municipalities, or cities, as in Brazil no distinction is made between town and city. As a federative system, each state and municipality has its own legislative chamber. While states and cities follow a unicameral system, the Federation itself has a bicameral system, with the National Congress divided into a Chamber of Deputies and the Federal Senate. These legislatures generate a great number of laws, or normative acts. The abundance of normative acts is very significant, considering that, in contrast with Common Law systems, Brazil’s legal system, based on the Civil Law, is characterized by the predominance of normative acts.
legal systems are necessary. Brazil is a country of continental proportions, composed of 27 states and more than five thousand municipalities, or cities, as in Brazil no distinction is made between town and city. As a federative system, each state and municipality has its own legislative chamber. While states and cities follow a unicameral system, the Federation itself has a bicameral system, with the National Congress divided into a Chamber of Deputies and the Federal Senate. These legislatures generate a great number of laws, or normative acts. The abundance of normative acts is very significant, considering that, in contrast with Common Law systems, Brazil’s legal system, based on the Civil Law, is characterized by the predominance of normative acts.
According to Edilenice Passos, “the proliferation of normative acts, of higher or lower hierarchy, eventually causes total chaos, for this big mass of juridical documents hampers the work of lawyers, of researchers, and of the very citizens, who are ruled by Brazilian laws.” Edilenice Passos also cites Arnoldo Wald, who, in 1969, was already alerting Brazilians that “the true legislative labyrinth created as a result of an inflation of statutes passed in recent years has turned the ruling Brazilian law into a patchwork, in which the mere legislative updating becomes a daily torture for a lawyer and a judge who are searching for the rules applicable to a specific subject, from among acts, supplementary acts, institutional acts, decree-laws, and other normative acts.”
Almost all Brazilian legal and legislative information is available through the Internet. However, this information is distributed among several thousand sites, each containing documents produced by a specific government institution. Thus, the relationships between acts of different institutions is not available explicitly, making it very hard to understand this “legal patchwork.”
Nowadays, much time is lost looking for this information, filtering the results of search engines. As Roy Tennant says, “Librarians like to search; everyone else likes to find,” and further adds: “People generally want to find everything they can on a topic, ranked by relevance and displayed in ways that make it easy to narrow in on their goal.”
Born to address these issues, LexML Brazil is an information network that aims to organize Brazil’s legislative and legal information. The project is an initiative of the “Comunidade TI Controle” (IT Control Community) and is being implemented by the Brazilian Federal Senate, through PRODASEN (the Senate’s special secretariat for information systems) and Interlegis (a virtual community of Brazilian legislatures).
LexML Brazil’s first product is the Legislative and Legal Information Portal, which opened on June 30, 2009, indexing 1.28 million documents. In September 2010, its index ranged through more than 1.5 million documents. By indexing the metadata collected from several institutions using the OAI-PMH protocol, the portal unifies access to a variety of legislative and legal information sources, which is a step toward the goal of guaranteeing Brazilians’ constitutional right of access to information.
LexML Portal
The LexML Portal home page layout is very simple and is similar to Google‘s main page. At this screen, it is possible to restrict the search to Legislation, Jurisprudence, or Bills.

The search results page allows the user to refine the search by using filters, according to his or her information requirements. Five filters are available: location, issuing authority, document type, date, and acronyms.
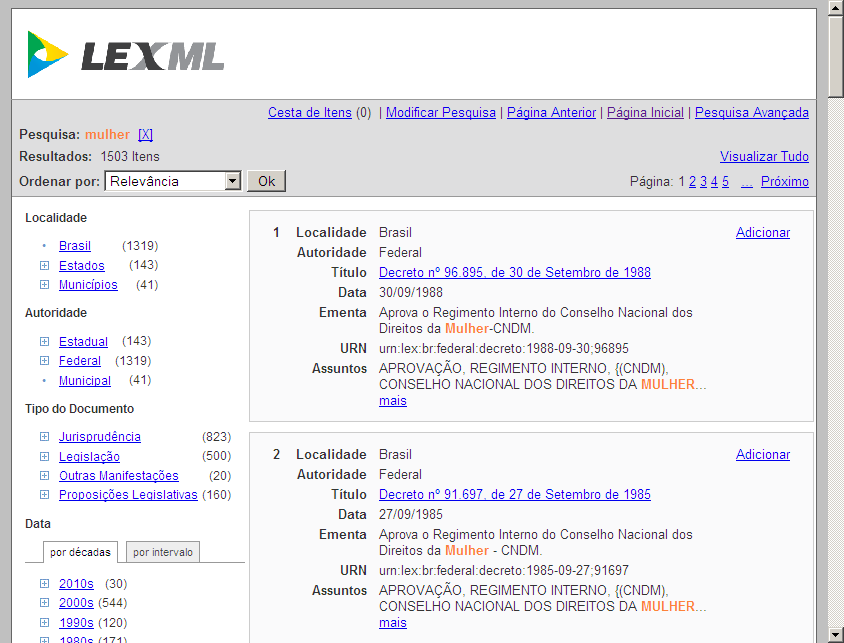
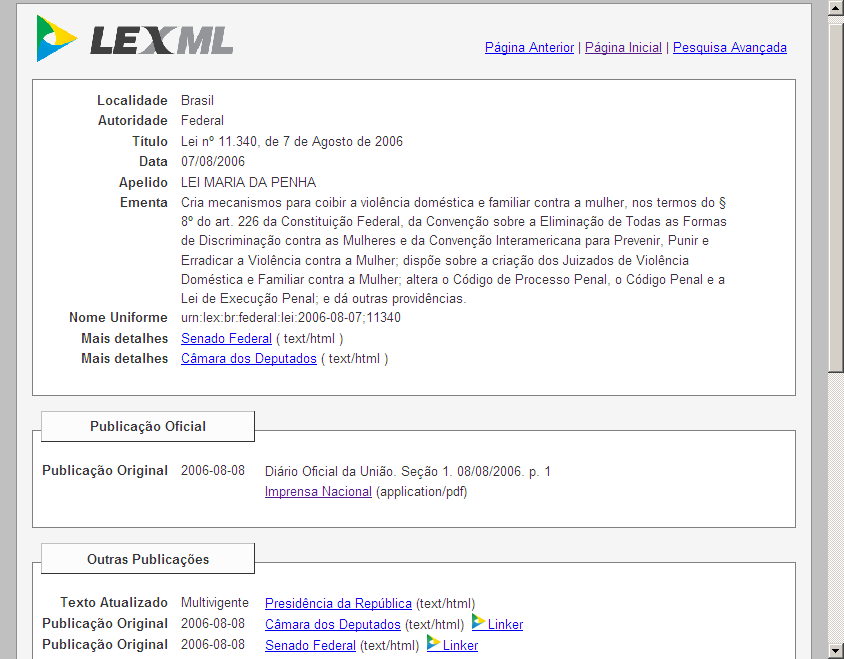
The detail page provides links to the official publication version of each document, and to other publications available in information systems of network participants, which, in this particular case, are: National Press, Presidency, Chamber of Deputies, and Federal Senate. General information about the document is available by clicking one of “Mais Detalhes (More details)” links, which directs the Web browser to the corresponding network participant’s metadata page. A service providing automatic identification of textual references can be activated by clicking the “Linker” label.
Semantic Interoperability
While systems interoperability and syntactic issues can be managed with the estabilished standards of representation, codification, and exchange (XML, METS, Unicode, OAI-PMH, etc.), structural and semantic interoperability demands the adoption of a reference model that allows the integration of several models and the use of a unified terminology for indexing different sources of information. According to Patel et al., the general purpose of semantic interoperability is “to support complex and advanced context-sensitive query processing over heterogeneous information resources.” Lack of semantic interoperability generates then the “information silos” problem, characterized by the lack of information integration and consequent inability to process complex queries.
The next section presents the design choices made by the LexML Brazil Project to address issues related to semantic interoperability using Ranganathan‘s “stratification planes” classification system, featuring: an idea plane, a verbal plane, and a notational plane.
Idea Plane
The idea plane is composed of the abstract entities of a domain, independently of how they are nominated or identified.
The metadata standards that propose to address interoperability issues do so either for a specific, restricted domain or for heterogeneous domains. Specialized metadata standards (MARC, EAD, MODS, etc.) allow different sources of information about specific domains (bibliographical or archival information) to be integrated and searched in an advanced form. On the other hand, the Dublin Core standard is one of the few that try to integrate arbitrarily heterogeneous sources using a minimum set of elements and qualifiers. Its characteristic simplicity enables easy adoption by multiple actors, but also hinders query processing, preventing the use of the rich chain of relationships among entities. The lack of generality or expressiveness of these standards precludes their use for achieving semantic interoperability of heterogeneous sources of legislative and legal information in Brazil.
An alternative is to use formal ontologies instead of metadata standards. According to Martin Doerr, “recently, more and more projects and theoreticians support the use of formal ontologies as common conceptual schema for information integration.” One such ontology, the CIDOC CRM model, was designed to help the integration, mediation, and interchange of heterogeneous cultural heritage information. It was developed in 1994 and has since been approved as the ISO 21127:2006 standard. The CIDOC CRM model is then a natural choice for conceptual schemas of legal and legislative information, if one considers that the text corpus consisting of a nation’s sources of law is a part of the nation’s cultural heritage information.
However, the CIDOC CRM “document” concept lacks the necessary detail needed to describe the relationships among the several information abstraction levels: work, expression, manifestation, and item. That requirement is fulfilled by the FRBRER entity-relationship model, which was considered as a reference model in earlier phases of the project (“An Adaptation of the FRBR Model to Legal Norms,” João Lima, Proceedings of the V Legislative XML Workshop, Florence, 2005) .
The FRBROO standard, an ontology created by a working group formed in 2003 by representatives of IFLA (International Federation of Library Associations and Institutions) and ICOM (International Council of Museums) for purposes of harmonizing both models, was adopted by the LexML project because it combines the advantages of both models while addressing their shortcomings. As such, FRBROO manifests a great affinity to the LexML domain (“A Time-aware Ontology for Legal Resources,” João Lima et al., Proceedings of the Tenth International ISKO Conference, 2008).
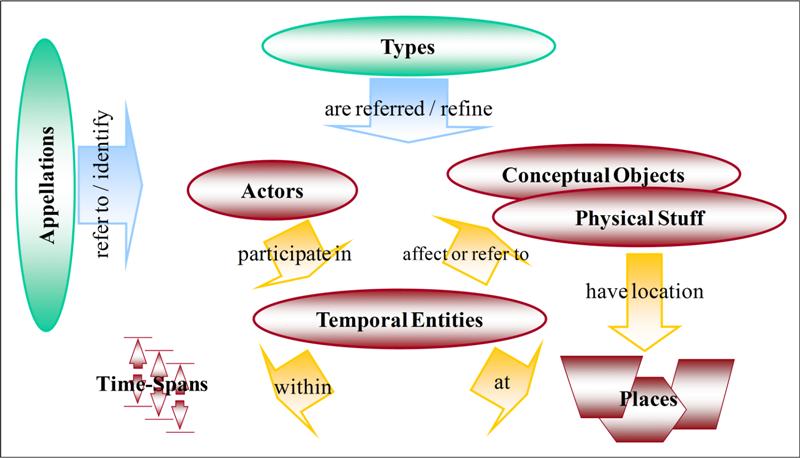
One of the great innovations of the CIDOC CRM model is the information structuring around temporal events, a central concept in the model. This contrasts with most other metadata models, which have resources as the central objects of interest. This innovative approach defines events as entities that connect actors, things (concrete and abstract), places, and time intervals.
{kind=link}
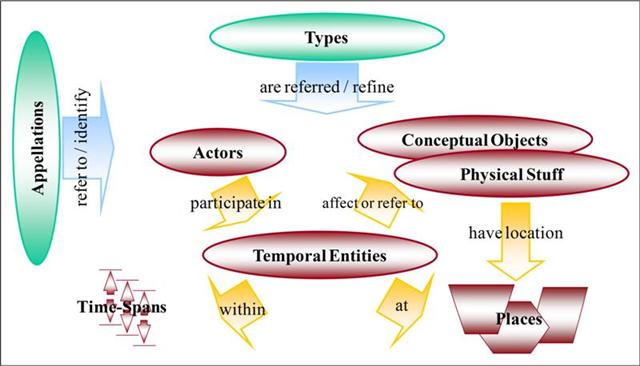
This particular emphasis could be criticized on the ground that the user is generally interested in a specific resource, such as the text of a law. However, the result of a search for information about a law is much more relevant if it includes an organized list of events related to the resource, along with the resource itself.
The importance of choosing a suitable reference model is easily observable in the present discussion about what particular syntax to use to codify persistent identifiers — urn:lex, LegisLink, Akoma Ntoso, etc. Before reaching the syntax level, such discussions should focus first on the idea plane, where a greater potential for integration exists. A consensus reached at this level would allow great flexibility for the specification of diverse persistent identifier syntaxes.
Verbal Plane
The CIDOC CRM ontology separates the class of types and denominations from other classes. Multiple names, identifiers, and types can be attributed to all entities of the CRM, allowing any domain class to be classified by several taxonomies and be known by multiple names and identifiers.
This approach is used in LexML to represent different terms that identify the same concepts. Six classes form LexML’s uniform resource identifiers: place, authority, type of document, event, type of content, and language. To externalize the LexML vocabularies specification, we recommend, and use, the W3C SKOS (Simple Knowledge Organization System).
Notational Plane
The definition of uniform and persistent identifiers is fundamental for the creation and maintenance of an information chain. Identifiers are already part of the legal domain. For identification purposes, numbers are attributed to rulings, decisions, abridgments, and bills, allowing references by means of textual remissions. In the computational environment, the creation of persistent and uniform identifiers allows not only identification and reference, but also access to documents by means of textual hyperlinks.
Based on the experience of the Italian project Norme in Rete with respect to URN (Uniform Resource Name) identifiers, LexML defines a grammar for the construction of identifiers for legislative and legal documents in Brazil. As an example, the name “urn:lex:br:federal:lei:1993-06-21;8666” identifies, in a persistent and unique way, the “Federal Act No. 8666, of June 21, 1993.” If all information systems agree with respect to the identifiers, it is possible to share descriptive metadata, as well as information about semantic relationships, such as regulation, amendment, abrogation, etc.
The Linker service, accessible through the LexML Portal (see, e.g., Act 11.705 without linker and Act 11.705 with linker), creates hyperlinks automatically through a dynamic textual analysis that identifies textual remissions of [i.e., citations to] normative documents. These hyperlinks can be used to navigate through textual remissions.
Future Directions
LexML 1.0 consists of the Search Portal, the Resolution Service, the Persistent Identifier, and the Linker Service. The next version, LexML 2.0, will go further: it will involve the development of open source tools for managing the complete text of documents encoded according to the LexML Brazil XML Schema, which was derived from the schemas of the Akoma Ntoso Project.
The complete management of document texts in a structured form has been a goal of the project since its inception. In as early as 2000, the Federal Constitution Portal was implemented following this idea. This portal allows the user to see all the versions of the constitutional text through a timeline, with the option to see the list of historical changes [see, e.g., art. 12] and with the ability to navigate bi-directional links [for example, in art. 154, click on the blue arrows].
During the development of that portal, taking into account the various forms of XML used to encode normative texts in many countries, and especially the experience of the Italian project Norme in Rete, a decision was made to make a unified portal and a persistent identifier a priority of the LexML project. Presently, our efforts to build open source tools for management of document texts are being renewed. One of these tools, a LexML Document Editor, will enable the authoring of legal texts as if using a word processor, but producing a structured document at the end. Another tool is the Compiler, which will semi-automatically generate modified versions of documents that have been updated by other legal acts. The Consolidator will help to simplify the display of legal information — and users’ experience of the legal system — through the consolidation of several related normative acts into a single act. The Comparator will be used to display the differences between versions of a document. The last tool, the Publisher, will be used to render XML content in different formats, such as html, PDF, PDF-A, EPUB, etc., with the ability to choose different views of the same text, such as the original text, the updated text as of a specific date, etc.
Last but not least, the Information Management Committee, which is a community of practice composed of librarians, archivists, and information analysts of several institutions of the three Brazilian governmental branches, interested in the management of legal and legislative information, is responsible for the definition of the priority and long range planning of the LexML Brazil Project.
[Editor’s Note: For documentation, schemas, and controlled vocabularies respecting LexML Brazil, please see the LexML Brazil Project Website. For more information on these issues, please see the following VoxPopuLII posts: John Sheridan on Legislation.gov.uk, Ivan Mokanov on CANLII‘s innovative legal citation system, Joe Carmel on LegisLink, and Robb Shecter on OregonLaws.org.]

The LexML Brazil core team, from left to right: João Lima (joaolima at senado.gov.br) is the leader of The LexML Project. His Information Science Ph.D. thesis details many of the concepts presented here; João Holanda (jholanda at senado.gov.br) holds a BSc in History from UnB; João Rafael (jrafael at senado.gov.br) holds a MSc in Computer Science from UFMG and a BSc in Computer Science from UnB; Marcos Fragomeni (fragomeni at senado.gov.br) holds a BSc in Computer Science from UnB.
VoxPopuLII is edited by Judith Pratt. Editor in chief is Robert Richards.
[…] » LexML Brazil Project VoxPopuLII blog.law.cornell.edu/voxpop/2010/10/15/lexml-brazil-project/ – view page – cached Published October 15, 2010 Legal XML , Legal identifiers , Legal metadata , Legal ontologies , Legal text processing , Legislative information systems , elegislation , elegislation systems , information retrieval , open source software , search Tags: João Lima, Legal identifiers, Legal URNs, LexML Brazil, URN:LEX Tweets about this link […]
[…] For more information on the LexML Project, please the project’s Website and Dr. Lima’s post about the project, at VoxPopuLII. […]