



 There have been a series of efforts to create a national legislative data standard – one master XML format to which all states will adhere for bills, laws, and regulations.Those efforts have gone poorly.
There have been a series of efforts to create a national legislative data standard – one master XML format to which all states will adhere for bills, laws, and regulations.Those efforts have gone poorly.
Few states provide bulk downloads of their laws. None provide APIs. Although nearly all states provide websites for people to read state laws, they are all objectively terrible, in ways that demonstrate that they were probably pretty impressive in 1995. Despite the clear need for improved online display of laws, the lack of a standard data format and the general lack of bulk data has enabled precious few efforts in the private sector. (Notably, there is Robb Schecter’s WebLaws.org, which provides vastly improved experiences for the laws of California, Oregon, and New York. There was also a site built experimentally by Ari Hershowitz that was used as a platform for last year’s California Laws Hackathon.)
A significant obstacle to prior efforts has been the perceived need to create a single standard, one that will accommodate the various textual legal structures that are employed throughout government. This is a significant practical hurdle on its own, but failure is all but guaranteed by also engaging major stakeholders and governments to establish a standard that will enjoy wide support and adoption.
What if we could stop letting the perfect be the enemy of the good? What if we ignore the needs of the outliers, and establish a “good enough” system, one that will at first simply work for most governments? And what if we completely skip the step of establishing a standard XML format? Wouldn’t that get us something, a thing superior to the nothing that we currently have?
The State Decoded
This is the philosophy behind The State Decoded. Funded by the John S. and James L. Knight Foundation, The State Decoded is a free, open source program to put legal codes online, and it does so by simply skipping over the problems that have hampered prior efforts. The project does not aspire to create any state law websites on its own but, instead, to provide the software to enable others to do so.
Still in its development (it’s at version 0.4), The State Decoded leaves it to each implementer to gather up the contents of the legal code in question and interface it with the program’s internal API. This could be done via screen-scraping off of an existing state code website, modifying the parser to deal with a bulk XML file, converting input data into the program’s simple XML import format, or by a few other methods. While a non-trivial task, it’s something that can be knocked out in an afternoon, thus avoiding the need to create a universal data format and to persuade Wexis to provide their data in that format.
The magic happens after the initial data import. The State Decoded takes that raw legal text and uses it to populate a complete, fully functional website for end-users to search and browse those laws. By packaging the Solr search engine and employing some basic textual analysis, every law is cross-referenced with other laws that cite it and laws that are textually similar. If there exists a repository of legal decisions for the jurisdiction in question, that can be incorporated, too, displaying a list of the court cases that cite each section. Definitions are detected, loaded into a dictionary, and make the laws self-documenting. End users can post comments to each law. Bulk downloads are created, letting people get a copy of the entire legal code, its structural elements, or the automatically assembled dictionary. And there’s a REST-ful, JSON-based API, ready to be used by third parties. All of this is done automatically, quickly, and seamlessly. The time elapsed varies, depending on server power and the length of the legal code, but it generally takes about twenty minutes from start to finish.
The State Decoded is a free program, released under the GNU Public License. Anybody can use it to make legal codes more accessible online. There are no strings attached.
It has already been deployed in two states, Virginia and Florida, despite not actually being a finished project yet.
State Variations
 The striking variations in the structures of legal codes within the U.S. required the establishment of an appropriately flexible system to store and render those codes. Some legal codes are broad and shallow (e.g., Louisiana, Oklahoma), while others are narrow and deep (e.g., Connecticut, Delaware). Some list their sections by natural sort order, some in decimal, a few arbitrarily switch between the two. Many have quirks that will require further work to accommodate.
The striking variations in the structures of legal codes within the U.S. required the establishment of an appropriately flexible system to store and render those codes. Some legal codes are broad and shallow (e.g., Louisiana, Oklahoma), while others are narrow and deep (e.g., Connecticut, Delaware). Some list their sections by natural sort order, some in decimal, a few arbitrarily switch between the two. Many have quirks that will require further work to accommodate.
For example, California does not provide a catch line for their laws, but just a section number. One must read through a law to know what it actually does, rather than being able to glance at the title and get the general idea. Because this is a wildly impractical approach for a state code, the private sector has picked up the slack – Westlaw and LexisNexis each write their own titles for those laws, neatly solving the problem for those with the financial resources to pay for those companies’ offerings. To handle a problem like this, The State Decoded either needs to be able to display legal codes that lack section titles, or pointedly not support this inferior approach, and instead support the incorporation of third-party sources of title. In California, this might mean mining the section titles used internally by the California Law Revision Commission, and populating the section titles with those. (And then providing a bulk download of that data, allowing it to become a common standard for California’s section titles.)
Many state codes have oddities like this. The State Decoded combines flexibility with open source code to make it possible to deal with these quirks on a case-by-case basis. The alternative approach is too convoluted and quixotic to consider.
Regulations
 There is strong interest in seeing this software adapted to handle regulations, especially from cash-strapped state governments looking to modernize their regulatory delivery process. Although this process is still in an early stage, it looks like rather few modifications will be required to support the storage and display of regulations within The State Decoded.
There is strong interest in seeing this software adapted to handle regulations, especially from cash-strapped state governments looking to modernize their regulatory delivery process. Although this process is still in an early stage, it looks like rather few modifications will be required to support the storage and display of regulations within The State Decoded.
More significant modifications would be needed to integrate registers of regulations, but the substantial public benefits that would provide make it an obvious and necessary enhancement. The present process required to identify the latest version of a regulation is the stuff of parody. To select a state at random, here are the instructions provided on Kansas’s website:
To find the latest version of a regulation online, a person should first check the table of contents in the most current Kansas Register, then the Index to Regulations in the most current Kansas Register, then the current K.A.R. Supplement, then the Kansas Administrative Regulations. If the regulation is found at any of these sequential steps, stop and consider that version the most recent.
If Kansas has electronic versions of all this data, it seems almost punitive not to put it all in one place, rather than forcing people to look in four places. It seems self-evident that the current Kansas Register, the Index to Regulations, the K.A.R. Supplement, and the Kansas Administrative Regulations should have APIs, with a common API atop all four, which would make it trivial to present somebody with the current version of a regulation with a single request. By indexing registers of regulations in the manner that The State Decoded indexes court opinions, it would at least be possible to show people all activity around a given regulation, if not simply show them the present version of it, since surely that is all that most people want.
A Tapestry of Data
In a way, what makes The State Decoded interesting is not anything that it actually does, but instead what others might do with the data that it emits. By capitalizing on the program’s API and healthy collection of bulk downloads, clever individuals will surely devise uses for state legal data that cannot presently be envisioned.
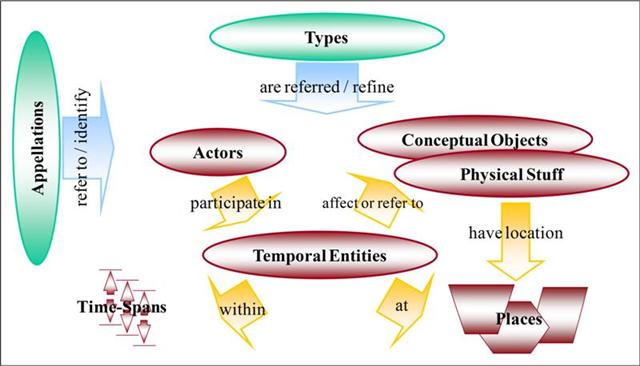
The structural value of state laws is evident when considered within the context of other open government data.

Major open government efforts are confined largely to the upper-right quadrant of this diagram – those matters concerned with elections and legislation. There is also some excellent work being done in opening up access to court rulings, indexing scholarly publications, and nascent work in indexing the official opinions of attorneys general. But the latter group cannot be connected to the former group without opening up access to state laws. Courts do not make rulings about bills, of course – it is laws with which they concern themselves. Law journals cite far more laws than they do bills. To weave a seamless tapestry of data that connects court decisions to state laws to legislation to election results to campaign contributions, it is necessary to have a source of rich data about state laws. The State Decoded aims to provide that data.
Next Steps
The most important next step for The State Decoded is to complete it, releasing a version 1.0 of the software. It has dozens of outstanding issues – both bug fixes and new features – so this process will require some months. In that period, the project will continue to work with individuals and organizations in states throughout the nation who are interested in deploying The State Decoded to help them get started.
Ideally, The State Decoded will be obviated by states providing both bulk data and better websites for their codes and regulations. But in the current economic climate, neither are likely to be prioritized within state budgets, so unfortunately there’s liable to remain a need for the data provided by The State Decoded for some years to come. The day when it is rendered useless will be a good day.
 Waldo Jaquith is a website developer with the Miller Center at the University of Virginia in Charlottesville, Virginia. He is a News Challenge Fellow with the John S. and James L. Knight Foundation and runs Richmond Sunlight, an open legislative service for Virginia. Jaquith previously worked for the White House Office of Science and Technology Policy, for which he developed Ethics.gov, and is now a member of the White House Open Data Working Group.
Waldo Jaquith is a website developer with the Miller Center at the University of Virginia in Charlottesville, Virginia. He is a News Challenge Fellow with the John S. and James L. Knight Foundation and runs Richmond Sunlight, an open legislative service for Virginia. Jaquith previously worked for the White House Office of Science and Technology Policy, for which he developed Ethics.gov, and is now a member of the White House Open Data Working Group.
[Editor’s Note: For topic-related VoxPopuLII posts please see: Ari Hershowitz & Grant Vergottini, Standardizing the World’s Legal Information – One Hackathon At a Time; Courtney Minick, Universal Citation for State Codes; John Sheridan, Legislation.gov.uk; and Robb Schecter, The Recipe for Better Legal Information Services. ]
VoxPopuLII is edited by Judith Pratt. Editors-in-Chief are Stephanie Davidson and Christine Kirchberger, to whom queries should be directed.



{kind=link}