Prosumption: shifting the barriers between information producers and consumers
One of the major revolutions of the Internet era has been the shifting of the frontiers between producers and consumers [1]. Prosumption refers to the emergence of a new category of actors who not only consume but also contribute to content creation and sharing. Under the umbrella of Web 2.0, many sites indeed enable users to share multimedia content, data, experiences [2], views and opinions on different issues, and even to act cooperatively to solve global problems [3]. Web 2.0 has become a fertile terrain for the proliferation of valuable user data enabling user profiling, opinion mining, trend and crisis detection, and collective problem solving [4].
The private sector has long understood the potentialities of user data and has used them for analysing customer preferences and satisfaction, for finding sales opportunities, for developing marketing strategies, and as a driver for innovation. Recently, corporations have relied on Web platforms for gathering new ideas from clients on the improvement or the development of new products and services (see for instance Dell’s Ideastorm; salesforce’s IdeaExchange; and My Starbucks Idea). Similarly, Lego’s Mindstorms encourages users to share online their projects on the creation of robots, by which the design becomes public knowledge and can be freely reused by Lego (and anyone else), as indicated by the Terms of Service. Furthermore, companies have been recently mining social network data to foresee future action of the Occupy Wall Street movement.
Even scientists have caught up and adopted collaborative methods that enable the participation of laymen in scientific projects [5].
Now, how far has government gone in taking up this opportunity?
Some recent initiatives indicate that the public sector is aware of the potential of the “wisdom of crowds.” In the domain of public health, MedWatcher is a mobile application that allows the general public to submit information about any experienced drug side effects directly to the US Food and Drug Administration. In other cases, governments have asked for general input and ideas from citizens, such as the brainstorming session organized by Obama government, the wiki launched by the New Zealand Police to get suggestions from citizens for the drafting of a new policing act to be presented to the parliament, or the Website of the Department of Transport and Main Roads of the State of Queensland, which encourages citizens to share their stories related to road tragedies.
Even in so crucial a task as the drafting of a constitution, government has relied on citizens’ input through crowdsourcing [6]. And more recently several other initiatives have fostered crowdsourcing for constitutional reform in Morocco and in Egypt .
It is thus undeniable that we are witnessing an accelerated redefinition of the frontiers between experts and non-experts, scientists and non-scientists, doctors and patients, public officers and citizens, professional journalists and street reporters. The ‘Net has provided the infrastructure and the platforms for enabling collaborative work. Network connection is hardly a problem anymore. The problem is data analysis.
In other words: how to make sense of the flood of data produced and distributed by heterogeneous users? And more importantly, how to make sense of user-generated data in the light of more institutional sets of data (e.g., scientific, medical, legal)? The efficient use of crowdsourced data in public decision making requires building an informational flow between user experiences and institutional datasets.
Similarly, enhancing user access to public data has to do with matching user case descriptions with institutional data repositories (“What are my rights and obligations in this case?”; “Which public office can help me”?; “What is the delay in the resolution of my case?”; “How many cases like mine have there been in this area in the last month?”).
From the point of view of data processing, we are clearly facing a problem of semantic mapping and data structuring. The challenge is thus to overcome the flood of isolated information while avoiding excessive management costs. There is still a long way to go before tools for content aggregation and semantic mapping are generally available. This is why private firms and governments still mostly rely on the manual processing of user input.
The new producers of legally relevant content: a taxonomy
Before digging deeper into the challenges of efficiently managing crowdsourced data, let us take a closer look at the types of user-generated data flowing through the Internet that have some kind of legal or institutional flavour.
One type of user data emerges spontaneously from citizens’ online activity, and can take the form of:
- platforms gathering open public data and comments over them (see for instance data-publica )
- legal expert blogs (blawgs)
- or the journalistic coverage of the legal system.
User data can as well be prompted by institutions as a result of participatory governance initiatives, such as:
- crowdsourcing (targeting a specific issue or proposal by government as an open brainstorming session)
- comments and questions addressed by citizens to institutions through institutional Websites or through e-mail contact.
This variety of media supports and knowledge producers gives rise to a plurality of textual genres, semantically rich but difficult to manage given their heterogeneity and quick evolution.
Managing crowdsourcing
The goal of crowdsourcing in an institutional context is to extract and aggregate content relevant for the management of public issues and for public decision making. Knowledge management strategies vary considerably depending on the ways in which user data have been generated. We can think of three possible strategies for managing the flood of user data:
Pre-structuring: prompting the citizen narrative in a strategic way
A possible solution is to elicit user input in a structured way; that is to say, to impose some constraints on user input. This is the solution adopted by IdeaScale, a software application that was used by the Open Government Dialogue initiative of the Obama Administration. In IdeaScale, users are asked to check whether their idea has already been covered by other users, and alternatively to add a new idea. They are also invited to vote for the best ideas, so that it is the community itself that rates and thus indirectly filters the users’ input.
The MIT Deliberatorium, a technology aimed at supporting large-scale online deliberation, follows a similar strategy. Users are expected to follow a series of rules to enable the correct creation of a knowledge map of the discussion. Each post should be limited to a single idea, it should not be redundant, and it should be linked to a suitable part of the knowledge map. Furthermore, posts are validated by moderators, who should ensure that new posts follow the rules of the system. Other systems that implement the same idea are featurelist and Debategraph [7].
While these systems enhance the creation and visualization of structured argument maps and promote community engagement through rating systems, they present a series of limitations. The most important of these is the fact that human intervention is needed to manually check the correct structure of the posts. Semantic technologies can play an important role in bridging this gap.
Semantic analysis through ontologies and terminologies
Ontology-driven analysis of user-generated text implies finding a way to bridge Semantic Web data structures, such as formal ontologies expressed in RDF or OWL, with unstructured implicit ontologies emerging from user-generated content. Sometimes these emergent lightweight ontologies take the form of unstructured lists of terms used for tagging online content by users. Accordingly, some works have dealt with this issue, especially in the field of social tagging of Web resources in online communities. More concretely, different works have proposed models for making compatible the so-called top-down metadata structures (ontologies) with bottom-up tagging mechanisms (folksonomies).
The possibilities range from transforming folksonomies into lightly formalized semantic resources (Lux and Dsinger, 2007; Mika, 2005) to mapping folksonomy tags to the concepts and the instances of available formal ontologies (Specia and Motta, 2007; Passant, 2007). As the basis of these works we find the notion of emergent semantics (Mika, 2005), which questions the autonomy of engineered ontologies and emphasizes the value of meaning emerging from distributed communities working collaboratively through the Web.
 We have recently worked on several case studies in which we have proposed a mapping between legal and lay terminologies. We followed the approach proposed by Passant (2007) and enriched the available ontologies with the terminology appearing in lay corpora. For this purpose, OWL classes were complemented with a has_lexicalization property linking them to lay terms.
We have recently worked on several case studies in which we have proposed a mapping between legal and lay terminologies. We followed the approach proposed by Passant (2007) and enriched the available ontologies with the terminology appearing in lay corpora. For this purpose, OWL classes were complemented with a has_lexicalization property linking them to lay terms.
The first case study that we conducted belongs to the domain of consumer justice, and was framed in the ONTOMEDIA project. We proposed to reuse the available Mediation-Core Ontology (MCO) and Consumer Mediation Ontology (COM) as anchors to legal, institutional, and expert knowledge, and therefore as entry points for the queries posed by consumers in common-sense language.
The user corpus contained around 10,000 consumer questions and 20,000 complaints addressed from 2007 to 2010 to the Catalan Consumer Agency. We applied a traditional terminology extraction methodology to identify candidate terms, which were subsequently validated by legal experts. We then manually mapped the lay terms to the ontological classes. The relations used for mapping lay terms with ontological classes are mostly has_lexicalisation and has_instance.
A second case study in the domain of consumer law was carried out with Italian corpora. In this case domain terminology was extracted from a normative corpus (the Code of Italian Consumer law) and from a lay corpus (around 4000 consumers’ questions).
In order to further explore the particularities of each corpus respecting the semantic coverage of the domain, terms were gathered together into a common taxonomic structure [8]. This task was performed with the aid of domain experts. When confronted with the two lists of terms, both laypersons and technical experts would link most of the validated lay terms to the technical list of terms through one of the following relations:
- Subclass: the lay term denotes a particular type of legal concept. This is the most frequent case. For instance, in the class objects, telefono cellulare (cell phone) and linea telefonica (phone line) are subclasses of the legal terms prodotto (product) and servizio (service), respectively. Similarly, in the class actors agente immobiliare (estate agent) can be seen as subclass of venditore (seller). In other cases, the linguistic structures extracted from the consumers’ corpus denote conflictual situations in which the obligations have not been fulfilled by the seller and therefore the consumer is entitled to certain rights, such as diritto alla sostituzione (entitlement to a replacement). These types of phrases are subclasses of more general legal concepts such as consumer right.
- Instance: the lay term denotes a concrete instance of a legal concept. In some cases, terms extracted from the consumer corpus are named entities that denote particular individuals, such as Vodafone, an instance of a domain actor, a seller.
- Equivalent: a legal term is used in lay discourse. For instance, contratto (contract) or diritto di recessione (withdrawal right).
- Lexicalisation: the lay term is a lexical variant of the legal concept. This is the case for instance of negoziante, used instead of the legal term venditore (seller) or professionista (professional).
The distribution of normative and lay terms per taxonomic level shows that, whereas normative terms populate mostly the upper levels of the taxonomy [9], deeper levels in the hierarchy are almost exclusively represented by lay terms.

Term distribution per taxonomic level
The result of this type of approach is a set of terminological-ontological resources that provide some insights on the nature of laypersons’ cognition of the law, such as the fact that citizens’ domain knowledge is mainly factual and therefore populates deeper levels of the taxonomy. Moreover, such resources can be used for the further processing of user input. However, this strategy presents some limitations as well. First, it is mainly driven by domain conceptual systems and, in a way, they might limit the potentialities of user-generated corpora. Second, they are not necessarily scalable. In other words, these terminological-ontological resources have to be rebuilt for each legal subdomain (such as consumer law, private law, or criminal law), and it is thus difficult to foresee mechanisms for performing an automated mapping between lay terms and legal terms.
Beyond domain ontologies: information extraction approaches
One of the most important limitations of ontology-driven approaches is the lack of scalability. In order to overcome this problem, a possible strategy is to rely on informational structures that occur generally in user-generated content. These informational structures go beyond domain conceptual models and identify mostly discursive, emotional, or event structures.
this problem, a possible strategy is to rely on informational structures that occur generally in user-generated content. These informational structures go beyond domain conceptual models and identify mostly discursive, emotional, or event structures.
Discursive structures formalise the way users typically describe a legal case. It is possible to identify stereotypical situations appearing in the description of legal cases by citizens (i.e., the nature of the problem; the conflict resolution strategies, etc.). The core of those situations is usually predicates, so it is possible to formalize them as frame structures containing different frame elements. We followed such an approach for the mapping of the Spanish corpus of consumers’ questions to the classes of the domain ontology (Fernández-Barrera and Casanovas, 2011). And the same technique was applied for mapping a set of citizens’ complaints in the domain of acoustic nuisances to a legal domain ontology (Bourcier and Fernández-Barrera, 2011). By describing general structures of citizen description of legal cases we ensure scalability.
Emotional structures are extracted by current algorithms for opinion- and sentiment mining. User data in the legal domain often contain an important number of subjective elements (especially in the case of complaints and feedback on public services) that could be effectively mined and used in public decision making.
Finally, event structures, which have been deeply explored so far, could be useful for information extraction from user complaints and feedback, or for automatic classification into specific types of queries according to the described situation.
Crowdsourcing in e-government: next steps (and precautions?)
Legal prosumers’ input currently outstrips the capacity of government for extracting meaningful content in a cost-efficient way. Some developments are under way, among which are argument-mapping technologies and semantic matching between legal and lay corpora. The scalability of these methodologies is the main obstacle to overcome, in order to enable the matching of user data with open public data in several domains.
However, as technologies for the extraction of meaningful content from user-generated data develop and are used in public-decision making, a series of issues will have to be dealt with. For instance, should the system developer bear responsibility for the erroneous or biased analysis of data? Ethical questions arise as well: May governments legitimately analyse any type of user-generated content? Content-analysis systems might be used for trend- and crisis detection; but what if they are also used for restricting freedoms?
The “wisdom of crowds” can certainly be valuable in public decision making, but the fact that citizens’ online behaviour can be observed and analysed by governments without citizens’ acknowledgement poses serious ethical issues.
Thus, technical development in this domain will have to be coupled with the definition of ethical guidelines and standards, maybe in the form of a system of quality labels for content-analysis systems.
[Editor’s Note: For earlier VoxPopuLII commentary on the creation of legal ontologies, see Núria Casellas, Semantic Enhancement of Legal Information… Are We Up for the Challenge? For earlier VoxPopuLII commentary on Natural Language Processing and legal Semantic Web technology, see Adam Wyner, Weaving the Legal Semantic Web with Natural Language Processing. For earlier VoxPopuLII posts on user-generated content, crowdsourcing, and legal information, see Matt Baca and Olin Parker, Collaborative, Open Democracy with LexPop; Olivier Charbonneau, Collaboration and Open Access to Law; Nick Holmes, Accessible Law; and Staffan Malmgren, Crowdsourcing Legal Commentary.]
[1] The idea of prosumption existed actually long before the Internet, as highlighted by Ritzer and Jurgenson (2010): the consumer of a fast food restaurant is to some extent as well the producer of the meal since he is expected to be his own waiter, and so is the driver who pumps his own gasoline at the filling station.
[2] The experience project enables registered users to share life experiences, and it contained around 7 million stories as of January 2011: http://www.experienceproject.com/index.php.
[3] For instance, the United Nations Volunteers Online platform (http://www.onlinevolunteering.org/en/vol/index.html) helps volunteers to cooperate virtually with non-governmental organizations and other volunteers around the world.
[4] See for instance the experiment run by mathematician Gowers on his blog: he posted a problem and asked a large number of mathematicians to work collaboratively to solve it. They eventually succeeded faster than if they had worked in isolation: http://gowers.wordpress.com/2009/01/27/is-massively-collaborative-mathematics-possible/.
[5] The Galaxy Zoo project asks volunteers to classify images of galaxies according to their shapes: http://www.galaxyzoo.org/how_to_take_part. See as well Cornell’s projects Nestwatch (http://watch.birds.cornell.edu/nest/home/index) and FeederWatch (http://www.birds.cornell.edu/pfw/Overview/whatispfw.htm), which invite people to introduce their observation data into a Website platform.
[6] http://www.participedia.net/wiki/Icelandic_Constitutional_Council_2011.
[7] See the description of Debategraph in Marta Poblet’s post, Argument mapping: visualizing large-scale deliberations (http://serendipolis.wordpress.com/2011/10/01/argument-mapping-visualizing-large-scale-deliberations-3/).
[8] Terms have been organised in the form of a tree having as root nodes nine semantic classes previously identified. Terms have been added as branches and sub-branches, depending on their degree of abstraction.
[9] It should be noted that legal terms are mostly situated at the second level of the hierarchy rather than the first one. This is natural if we take into account the nature of the normative corpus (the Italian consumer code), which contains mostly domain specific concepts (for instance, withdrawal right) instead of general legal abstract categories (such as right and obligation).
REFERENCES
Bourcier, D., and Fernández-Barrera, M. (2011). A frame-based representation of citizen’s queries for the Web 2.0. A case study on noise nuisances. E-challenges conference, Florence 2011.
Fernández-Barrera, M., and Casanovas, P. (2011). From user needs to expert knowledge: Mapping laymen queries with ontologies in the domain of consumer mediation. AICOL Workshop, Frankfurt 2011.
Lux, M., and Dsinger, G. (2007). From folksonomies to ontologies: Employing wisdom of the crowds to serve learning purposes. International Journal of Knowledge and Learning (IJKL), 3(4/5): 515-528.
Mika, P. (2005). Ontologies are us: A unified model of social networks and semantics. In Proc. of Int. Semantic Web Conf., volume 3729 of LNCS, pp. 522-536. Springer.
Passant, A. (2007). Using ontologies to strengthen folksonomies and enrich information retrieval in Weblogs. In Int. Conf. on Weblogs and Social Media, 2007.
Poblet, M., Casellas, N., Torralba, S., and Casanovas, P. (2009). Modeling expert knowledge in the mediation domain: A Mediation Core Ontology, in N. Casellas et al. (Eds.), LOAIT- 2009. 3rd Workshop on Legal Ontologies and Artificial Intelligence Techniques joint with 2nd Workshop on Semantic Processing of Legal Texts. Barcelona, IDT Series n. 2.
Ritzer, G., and Jurgenson, N. (2010). Production, consumption, prosumption: The nature of capitalism in the age of the digital “prosumer.” In Journal of Consumer Culture 10: 13-36.
Specia, L., and Motta, E. (2007). Integrating folksonomies with the Semantic Web. Proc. Euro. Semantic Web Conf., 2007.
 Meritxell Fernández-Barrera is a researcher at the Cersa (Centre d’Études et de Recherches de Sciences Administratives et Politiques) -CNRS, Université Paris 2-. She works on the application of natural language processing (NLP) to legal discourse and legal communication, and on the potentialities of Web 2.0 for participatory democracy.
Meritxell Fernández-Barrera is a researcher at the Cersa (Centre d’Études et de Recherches de Sciences Administratives et Politiques) -CNRS, Université Paris 2-. She works on the application of natural language processing (NLP) to legal discourse and legal communication, and on the potentialities of Web 2.0 for participatory democracy.
VoxPopuLII is edited by Judith Pratt. Editor-in-Chief is Robert Richards, to whom queries should be directed. The statements above are not legal advice or legal representation. If you require legal advice, consult a lawyer. Find a lawyer in the Cornell LII Lawyer Directory.





 Michael Curtotti is undertaking a PhD in the Research School of Computer Science at the Australian National University. His co-authored publications on legal informatics include: A Right to Access Implies a Right to Know: An Open Online Platform for Readability Research; Enhancing the Visualization of Law and A corpus of Australian contract language: description, profiling and analysis. He holds a Bachelor of Laws and a Bachelor of Commerce from the University of New South Wales, and a Masters of International Law from the Australian National University. He works part-time as a legal adviser to the ANU Students Association and the ANU Post-graduate & research students Association, providing free legal services to ANU students.
Michael Curtotti is undertaking a PhD in the Research School of Computer Science at the Australian National University. His co-authored publications on legal informatics include: A Right to Access Implies a Right to Know: An Open Online Platform for Readability Research; Enhancing the Visualization of Law and A corpus of Australian contract language: description, profiling and analysis. He holds a Bachelor of Laws and a Bachelor of Commerce from the University of New South Wales, and a Masters of International Law from the Australian National University. He works part-time as a legal adviser to the ANU Students Association and the ANU Post-graduate & research students Association, providing free legal services to ANU students.


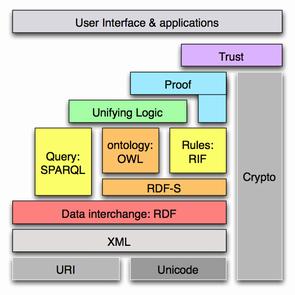
 Though it may seem here like too much technology for such a small and obvious task, it is essential where we scale up our queries and inferences on
Though it may seem here like too much technology for such a small and obvious task, it is essential where we scale up our queries and inferences on 
