



VoxPopuLII
Is it good enough for the law to be written for lawyers?

c.c. BY-SA 3.0. wikipedia.org
If you think that law isn’t written for lawyers, try reading some. It can even start looking normal after a while (say about the length of time it takes to get through law degree). But research on the main street impact of legal language suggests that for most people, the law is likely to be either incomprehensible or very hard to read.
This problem is a focus of a research project which a team of us at ANU and Cornell LII have been addressing over the past months (Eric McCreath (Australian National University, Research School of Computer Science), Wayne Weibel (Cornell University Law School, Legal Information Insitute), Nic Ceynowa (LII), Sara Frug (LII), Tom Bruce (LII) and myself (ANU)). With the generous help of thousands of LII users, as part of a citizen science project, we’ve been collecting data on the readability of law as well as demographic data about the users of law.
If you are concerned about access to law, and many are, the current situation is not really good enough. Whether you tend to ‘human rights’, ‘democratic values’, ‘economic efficiency’, ‘rule of law’ or are just wanting to make sure your hapless minions follow your every command, you’ll be able to think of a good reason why the law should be more accessible (readable) than it is.
Of course the problem has been around for a very long time, and plain language is a standing goal of many legislative drafting offices. Reform efforts have been underway since the middle ages. Certainly legal language has improved considerably, particularly as a result of 19th and 20th century reforms with that goal in mind. Still, the law can’t be said to be readily accessible to the general public, in the sense of its readability.
What has changed that makes the problem more urgent today is that the general public can now at least get to the law. That’s the revolution that’s been achieved by online publishers of the law, including the Free Access to Law Movement and official and commercial law publishers. As the UK’s First Parliamentary Counsel observed last year:
Legislation affects us all. And increasingly, legislation is being searched for, read and used by a broad range of people. It is no longer confined to professional libraries; websites like legislation.gov.uk have made it accessible to everyone. So the digital age has made it easier for people to find the law of the land; but once they have found it, they may be baffled. The law is regarded by its users as intricate and intimidating.
In 2010, the Plain Writing Act was adopted by the US Congress with the aim of improving government writing. Sad to say, the Act itself is no model of plain language. Section, sub-section and paragraph roll on, line after line, provision after convoluted provision. In substance they say not much more than: write clearly so that the public can understand and use what you write. Didn’t anyone see the irony? Then again, reality check, most legislation is never read by the people who vote to make it law. Just to make sure the drawbridge was well and truly up, if you read through to the fine print at the end there is an important rider. What happens if no one can understand what the law is supposed to mean? Well, nothing a judge can do about it. Great aspiration, but …
A sea change could be on the way, though. The Good Law initiative is one great example of efforts to address the complexity and readability of legislation. What is significant is that how we are thinking about legal rules is changing. Official publishers of the law are beginning to talk about the law as if it’s data. The UK National Archives Office has even published an API — Application Programmers Interface (basically a ‘how to’ for developers who want to use the “data”).So now we’re thinking of law as data. And we’re going to unleash computer scientists on it, to do whatever their imaginations can come up with. Bommarito and Katz‘ work on the legal code as a mathematical network is a great example of the virtually infinite possibilities.
Our own research uses the potential of computational technologies in another way. Online legal sites are not just ‘documents’. They are places where people are actively interacting with the law. We used crowd-sourcing to engage with this audience, asking them to rate law on readability characteristics as well as exploring the demographics of who uses the law. Our aim was to develop a labelled dataset that could be used as input to machine learning. “Labelled data” is machine learning gold — hard to get, but if you can you get it, you can use it to make predictions about what human judges would say. In our case we are trying to predict whether a legal sentence will be readable or not.
In the process we learned quite a bit about the audience using the law, and about which law they use. Scouring the Google Analytics data, it became obvious that the law is not equally read. We may all be equal before the law, but the law is not equal before us. Just 37 sections of the US Code account for almost 10% of the page visits to US code pages (there are about 65,000). So a tiny fraction of the Code is being read all the time. On the other hand there are huge swathes of the Code that hardly ever see the light of a back illuminated screen. This is not trivial news. Computer scientists love lists. Prioritised lists get their own special lectures for first year CS students — and here we have a prioritized list. You want to know what law is at the top of your priority list — the users will tell you. If you’re concerned with cleaning up the law code or making it easier to understand, there’s useful stuff here.
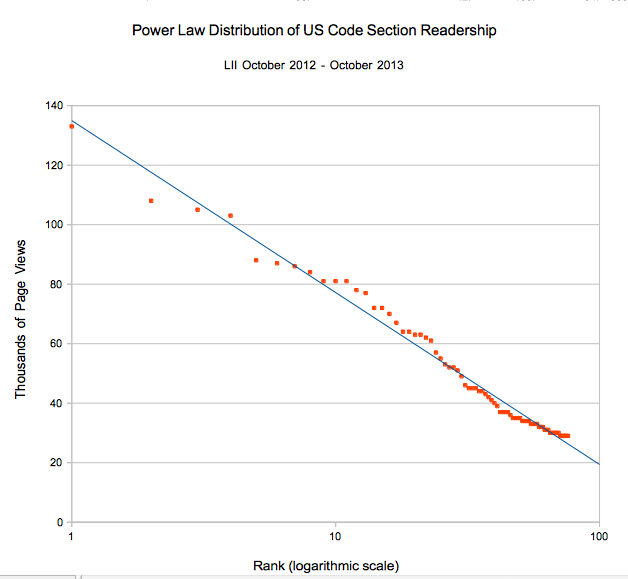
Ranking of sections by frequency of readership (on a logarithmic scale)
It will be no surprise that we found that law is harder for just about every part of the community than legal professionals. What was surprising was that legal professionals (including law students), turn out to be a minority of those interested enough to respond, on the LII site at least.
These were just a few of the demographic insights we were able to draw.
On the machine learning front, we were able to show that machine learning can improve on traditional readability metrics in predicting language difficulty (they’ve long been regarded as suspect in application to legal texts anyway). That said, it’s early days and we would like to extend the research we have done so far. There is a lot of potential for future research applying computational techniques to the readability of law. A co-authored publication further describing the research introduced in this article will be presented at this year’s Law Via the Internet Conference being held at the end of September.
But while we’re thinking about it, there are other ways to think about `access’ to law. What if instead of writing the law, it was visualized? You know — like in pictures. Before you storm off in contempt, note this: research is validating that pictures can improve user experience — for example in the contract space, where what your clients think of your contract can impact on your bottom line.
It’s radical enough unleashing computer scientists on legal rules. What might the law look like if we try thinking like designers? ‘User experience’ of legal rules? That one didn’t come up in law school. We’re in some surreally different world at this point. Designers create artefacts for people to use which are optimised for functionality, beauty and other characteristics –- not things that are meant to tell people what to do. ‘User experience’ is their kind of thinking.
As readers of Vox Pop will know, the idea of legal design is starting to get traction. Helena Haapio and Stefania Passera’s great article on legal design covers some of the field. An article they jointly published last year points out some of the benefits of visualization. Earlier this year, we worked on a joint paper exploring the feasibility of automating legal visualization. We were able to demonstrate the automation of visualization of clauses, such as a contract term clause, a liquidated damages clause or a payment clause. Visit our proof of concept site, where you can play with visualizing different options.
OK. So perhaps some of the above reads like we’re on the up-slope of the hype curve. But that of course is the fun. For those of us who’ve spent many years in the law, looking at the law from a different professional paradigm can help us see things that didn’t stand out before. It certainly enjoyable and brings a breath of fresh air to the law.
 Michael Curtotti is undertaking a PhD in the Research School of Computer Science at the Australian National University. His co-authored publications on legal informatics include: A Right to Access Implies a Right to Know: An Open Online Platform for Readability Research; Enhancing the Visualization of Law and A corpus of Australian contract language: description, profiling and analysis. He holds a Bachelor of Laws and a Bachelor of Commerce from the University of New South Wales, and a Masters of International Law from the Australian National University. He works part-time as a legal adviser to the ANU Students Association and the ANU Post-graduate & research students Association, providing free legal services to ANU students.
Michael Curtotti is undertaking a PhD in the Research School of Computer Science at the Australian National University. His co-authored publications on legal informatics include: A Right to Access Implies a Right to Know: An Open Online Platform for Readability Research; Enhancing the Visualization of Law and A corpus of Australian contract language: description, profiling and analysis. He holds a Bachelor of Laws and a Bachelor of Commerce from the University of New South Wales, and a Masters of International Law from the Australian National University. He works part-time as a legal adviser to the ANU Students Association and the ANU Post-graduate & research students Association, providing free legal services to ANU students.
—————————
Other related posts on VoxPopuLII on this topic include Law in the Last-Mile: The Potential of Mobile Integration into Legal Services by Sean Martin McDonald, Incomprehension Compounded by Mistranslation – The Imperatives of Access to Legal Information in South Africa by Eve Gray and Accessible Law by Nick Holmes
VoxPopuLII is edited by Judith Pratt. Editors-in-Chief are Stephanie Davidson and Christine Kirchberger, to whom queries should be directed.
Sorry, the comment form is closed at this time.