



In this post, I will describe how natural language processing can help in creating computer systems dealing with the law.
 A lot of computer systems are being designed to help users deal with legal texts — accessing, understanding, or applying them. [Editor’s Note: Michael Poulshock’s Jureeka is an example of a system that automates the application of legal texts.] Other systems — such as DALOS — are about creating legal texts, providing support for the writers, or simulating the effects of a text. Such systems are based on something more than “just” the legal text: there is XML mark-up, an OWL ontology, or a representation of the rules in SWRL or some programming language. This means that any piece of legislation that you want to use on your computer system needs to be translated into this computer representation.
A lot of computer systems are being designed to help users deal with legal texts — accessing, understanding, or applying them. [Editor’s Note: Michael Poulshock’s Jureeka is an example of a system that automates the application of legal texts.] Other systems — such as DALOS — are about creating legal texts, providing support for the writers, or simulating the effects of a text. Such systems are based on something more than “just” the legal text: there is XML mark-up, an OWL ontology, or a representation of the rules in SWRL or some programming language. This means that any piece of legislation that you want to use on your computer system needs to be translated into this computer representation.
We try to support this translation using natural language processing, so that (part of) the translation can be done by a computer. This automation should have a number of advantages. First of all, computers are cheaper than human experts, and automating the process should reduce the amount of resources needed for this task. Second, the models that are produced by automated processes are more consistent; human experts may treat two similar sentences differently, but a computer program will always behave the same. Finally, an approach employing structures ensures that there is a clear mapping between the elements of the computer model and the original text.
Natural Language Processing isn’t perfect yet: computers cannot understand human language. However, legal text is quite structured, and offers a lot more handholds for automated translation than, say, a novel.
Document Structure
The first step that we will have to undertake is to determine the structure of the document. Online services like Legislation.gov.uk and wetten.nl can make it easier to access legal documents because they can point you to the right part of the document (such as a chapter, paragraph, sentence, etc.). In most law texts, the structure has been made explicit using clear headings, like: Chapter 1 or Chapter 1. General Provisions. So, in order to detect structure, we need to detect these headings. This means we’ll need to search the document for lines starting with Chapter, followed by some designation (which we refer to as an index), and perhaps followed by some text – say, the title of the chapter. The index can  be a lot of things: Arabic numbers (1, 2, 3, …), Roman numbers (I, II, III, …) or letters (a, b, c, …). Sometimes the index is an ordinal appearing before the chapter label: First chapter. It may even be a combination of several numbers and letters (5.2a). This is not a great problem, as we can more or less assume that whatever follows the word Chapter is the index.
be a lot of things: Arabic numbers (1, 2, 3, …), Roman numbers (I, II, III, …) or letters (a, b, c, …). Sometimes the index is an ordinal appearing before the chapter label: First chapter. It may even be a combination of several numbers and letters (5.2a). This is not a great problem, as we can more or less assume that whatever follows the word Chapter is the index.
The main problem with this approach is that there are also regular sentences that start with the word Chapter, and we need to separate those out. To do so, we can use some heuristics: A title will not end with a full stop (.); a heading will always start on a new line; etc.
 This procedure to find the headings for chapters is repeated to find headings for sections, subsections, etc. Also, some sections (like numbered paragraphs or list items) will not have a full heading, but just a number, which we also need to recognise. Finally, some sections don’t have a heading but can be recognised because they start with a fixed language pattern. For example, a preamble in a (recent) Dutch Law — such as this — will start with: We, Beatrix, Queen of the Netherlands, Princess of Orange-Nassau, etc. etc. etc.
This procedure to find the headings for chapters is repeated to find headings for sections, subsections, etc. Also, some sections (like numbered paragraphs or list items) will not have a full heading, but just a number, which we also need to recognise. Finally, some sections don’t have a heading but can be recognised because they start with a fixed language pattern. For example, a preamble in a (recent) Dutch Law — such as this — will start with: We, Beatrix, Queen of the Netherlands, Princess of Orange-Nassau, etc. etc. etc.
This procedure assumes that the input for the process is just text. Many documents will contain more information — such as textual markup — and headings may be more easily identified because they are marked as bold text, or even as headings. So, in situations where the input is made up of documents that are marked-up in a consistent way, it may be easier to recognise the patterns by taking layout into account in addition to text.
To actually find the patterns, we can use existing toolkits like GATE. After the patterns have been found, and the structure has been recognised, we can store it using a format such as MetaLex.
References
The second step is to detect the references from a portion of a law text to other portions of that text, or from a law text to other texts. References, like headings, follow a pattern. The simplest patterns are rather similar to headings; the text chapter 13 is probably a reference, unless it is part of a heading.  Just like headings, basic references consist of a label (section, chapter, article) and an index (13, 13.2.1, XIII, m). And, just as with headings, we can find the references by looking for these patterns in the text.
Just like headings, basic references consist of a label (section, chapter, article) and an index (13, 13.2.1, XIII, m). And, just as with headings, we can find the references by looking for these patterns in the text.
However, this is only the simplest form of references. Besides references to a specific section, such as chapter 13, there are of course also references to a complete law. Some of these references follow a pattern as well, such as the law of October 1st, 2007. Most laws are cited by means of a citation title, though, such as the Railroad Act. Such titles can contain all kinds of words, and they don’t follow a strict pattern. Thus, such references cannot be detected using patterns. Instead, we use a list containing all (citation) titles to detect such references.
Other, more complex references contain multiple references in one statement, such as articles 13 and 14, or multiple levels: article 13, item e, of the Railroad Act, or even more complex combinations of the two: articles 13, item e, 14, item f, 15 and 16, items a and b, of the Railroad Act. Though more complex than the simple combination of label and index, these references still follow clear (sometimes recurring) patterns, and can be found in the text by searching for such patterns.
At the Leibniz Center for Law, we’ve created a parser based on these patterns, which had an accuracy of over 95%. For each reference found, we can construct some standardised name, and store it. With this technology, not only can we add hyperlinks to documents; we can also search for documents that refer to some specific document.
Classification
Now that we’ve got the structure and links in place, it’s time to start with the actual meaning of the text. Rather than tackling the entire text as a whole, we’ve selected sentences as the basic building blocks, and we attempt to create computer models for individual sentences first. Later, we can integrate those individual models to a complete model.
As a first step in creating the models, we start by assigning a broad meaning, or classification, to each sentence. Does the sentence give a definition for a concept, describe an obligation, or make a change in another law? In total, we distinguish fourteen different classes of sentences that appear in Dutch law texts. The next step in our automated approach is to assign a class to each sentence automatically.
To do so, we turn once again to language patterns. Legal language is rather strict, and legislative drafters don’t vary their language a lot — in a novel, variation may make for a more appealing text, but in a law, variation invites ambiguity. In fact, there are official Guidelines for Legislative Drafting that (among other things) reduce the variety of texts used. [Editor’s Note: For example, drafters of legislation in the U.S. House of Representatives Office of the Legislative Counsel have used Donald Hirsch’s Drafting Federal Law.] This means that for each of our classes, there’s a rather limited set of language patterns used. For example, definitions will look like one of these:
Under … is understood …
This law understands under … …
There are some variations in word order, but in the end, a small set of patterns is sufficient to describe all commonly used phrases. There is only one class of sentences where we cannot define a full set of patterns: obligations. In Dutch laws, obligations are often expressed without signal words like must or is obliged to. Instead, the obligations are presented as a fact:
No bodies are buried on a closed cemetery.
However, since the obligations are the only sentences lacking all-compassing patterns, we will assume that any sentence that does not mark a pattern is one of these obligations.
Based on the patterns found, we’ve created a classifier that attempts to sort sentences into these different classes. This classifier has an accuracy of 91%, and we expect that this can improved a bit further.
(As a side note: For classification tasks as these, a machine learning approach is often preferred; see, e.g., here. With such an approach, you provide the computer, not with patterns, but with a bunch of sample sentences. The computer will then extract its own patterns from those sentences, and use these to classify any new sentences. We’ve tried this approach as well (using the toolkit WEKA), and reached similarly accurate results.)
Modelling
Having classified the sentences, we now want to create models of the sentences. In essence, this means breaking down each sentence into smaller components and defining relationships between them. In some cases, the patterns used to classify the sentence already give us sufficient information to break up the sentence. Suppose we have a sentence like:
In article 7.12, sub one, second sentence, «article 7.3b» is replaced by: article 7.3c.
We classify this sentence as a replacement because of the text is replaced by. We can then also conclude that the text between angle quotes is the text to be replaced, the text following the colon is the replacing text, and the reference preceding it (which we’ve already detected) is the location where the replacement should take place.
This works fine for sentences that are somehow “about” the law. But for sentences that deal with some other domain, such as taxes, traffic, or commerce, we cannot predict all the elements. These sentences could be about anything — and statutes are full of such sentences. For such sentences, we need to follow a generic method. The aim is to model rules as a situation or action that is allowed or not allowed, similar to the models created in the HARNESS system of the ESTRELLA project. For example, for an obligation, we assume that the sentence describes some action that must be done.  We try to identify who should be doing the action, and what other elements are involved. Thus, for the sentence:
We try to identify who should be doing the action, and what other elements are involved. Thus, for the sentence:
Our Minister issues a warrant to the negligent person.
we would like to extract the following information:
Obligation
Action: Issue
Agent: Our Minister
Patient: Warrant
Recipient: Negligent person
(Such a table, or frame, is not the same as a computer model, but has all the elements needed to create one.)
Now, identifying these different elements of the sentence (agent, patient, recipient) is something that computer linguists have already worked on for a long time, which means we do not have to start from scratch. Instead, we can use existing parsers to do much of the work for us. For our Dutch laws, we use the Alpino parser. 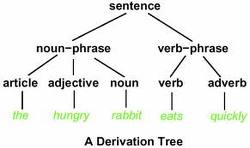 Such a parser will create a parse tree of a sentence. In this parse tree, the sentence will be split up in parts. The parser can identify which part is the subject, the direct object, the indirect object, etc. Based on this information, we can determine the agent, patient, and recipient (so-called semantic roles). In a sentence with a verb in the active voice, the subject is the agent, the direct object is the patient, and the indirect object is the recipient. Furthermore, the parser will determine the relationship between words, such as an adjective that modifies a noun. This information, too, helps us to make more accurate models.
Such a parser will create a parse tree of a sentence. In this parse tree, the sentence will be split up in parts. The parser can identify which part is the subject, the direct object, the indirect object, etc. Based on this information, we can determine the agent, patient, and recipient (so-called semantic roles). In a sentence with a verb in the active voice, the subject is the agent, the direct object is the patient, and the indirect object is the recipient. Furthermore, the parser will determine the relationship between words, such as an adjective that modifies a noun. This information, too, helps us to make more accurate models.
We start out with the output of these parsers, and then try to extract all terms that have some more significance. If we want an application to compute whether or not a situation is allowed, a word like car can be treated in a generic way, but terms like allowed and not some special attention.
To Be Continued…
We still need to refine the method for making these models, and evaluate the results. After that, the individual models will need to be merged. But even as things stand now, we think these tools will help with getting legal text from paper into your computer systems.
[Editor’s Note: For more information about this topic, please see Dr. Adam Wyner’s post, Weaving the Legal Semantic Web with Natural Language Processing.]
 Emile de Maat is a researcher at the Leibniz Center for Law (University of Amsterdam). His research focuses on the automatic extraction of metadata and meaning from legal sources.
Emile de Maat is a researcher at the Leibniz Center for Law (University of Amsterdam). His research focuses on the automatic extraction of metadata and meaning from legal sources.
VoxPopuLII is edited by Judith Pratt. Editor in chief is Robert Richards.