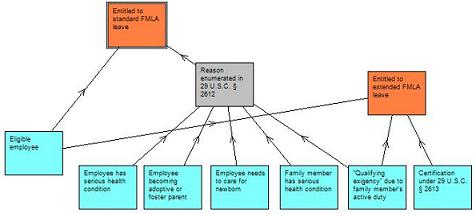
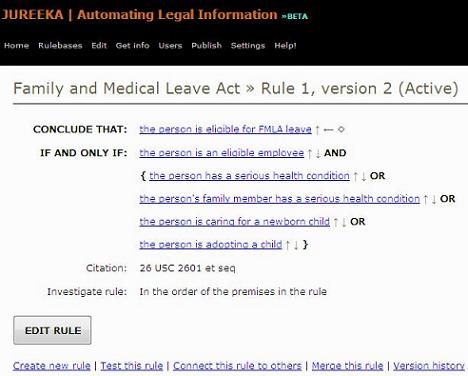
Ending up in legal informatics was probably more or less inevitable for me, as I wanted to study both law and electrical engineering from early on, and I just hoped that the combination would start making some sense sooner or later. ICT law (which I still pursue sporadically) emerged as an obvious choice, but AI and law seemed a better fit for my inner engineer.
The topic for my (still ongoing-ish) doctoral project just sort of emerged. Reading through the books recommended by my master’s thesis supervisor (professor Peter Blume in Copenhagen) a sentence in Cecilia Magnusson Sjöberg‘s dissertation caught my eye: “According to Bench-Capon and Sergot, fuzzy logic is unsuitable for modelling vagueness in law.” (translation ar) Having had some previous experiences with fuzzy control, this seemed like an interesting question to study in more detail. To me, vagueness and uncertainty did indeed seem like good places to use fuzzy logic, even in the legal domain.
After going through loads of relevant literature, I started looking for an example domain to do some experiments. The result was MOSONG, a fairly simple model of trademark similarity that used Type-2 fuzzy logic to represent both vagueness and uncertainty at the same time. Testing MOSONG yielded perfect results on the first validation set as well, which to me seemed more suspicious than positive. If the user/coder could decide the cases correctly without the help of the system, would it not affect the coding process as well? As a consequence I also started testing the system on a non-expert population (undergraduates, of course), and the performance started to conform better to my expectations.
My original idea for the thesis was to look at different aspects of legal knowledge by building a few working prototypes like MOSONG and then explaining them in terms of established legal theory (the usual suspects, starting from Hart, Dworkin, and Ross). Testing MOSONG had, however, made me perhaps more attuned to the perspective of an extremely naive reasoner, certainly a closer match for an AI system than a trained professional. From this perspective I found conventional legal theory thoroughly lacking, and so I turned to the more general psychological literature on reasoning and decision-making. After all, there is considerable overlap between cognitive science and artificial intelligence as multidisciplinary ventures. Around this time, the planned title of my thesis also received a subtitle, thus becoming Fuzzy Systems and Legal Knowledge: Prolegomena to a Cognitive Theory of Law, and a planned monograph morphed into an article-based dissertation instead.
One particularly useful thing I found was the dual-process theory of cognition, on which I presented a paper at IVR-2011 just a couple of months before Daniel Kahneman’s Thinking, Fast and Slow came out and everyone started thinking they understood what System 1 and System 2 meant. In my opinion, the dual-process theory has important implications for AI and law, and also explains why it has struggled to create widespread systems of practical utility. Representing legal reasoning only in classically rational System 2 terms may be adequate for expert human reasoners (and simple prototype systems), but AI needs to represent the ecological rationality (as opposed to the cognitive biases) of System 1 as well, and to do this properly, different methods are needed, and on a different scale. Hello, Big Dada!
In practice this means that the ultimate way to properly test one’s theories of legal reasoning computationally is through a full-scale R&D process of an AI system that hopefully does something useful. In an academic setting, doing the R part is no problem, but the D part is a different matter altogether, both because much of the work required can be fairly routine and too uninteresting from a publication standpoint, and because the muchness itself makes the project incompatible with normal levels of research funding. Instead, typically, an interested external recipient is required in order to get adequate funding. A relevant problem domain and a base of critical test users should also follow as a part of the bargain.
In the case of legal technology, the judiciary and the public administration are obvious potential recipients. Unfortunately, there are at least two major obstacles for this. One is attitudinal, as exemplified by the recent case of a Swedish candidate judge whose career path was cut short after creating a more usable IR system for case law on his own initiative. The other one is structural, with public sector software procurement in general in a state of crisis due to both a limited understanding of how to successfully develop software systems that result in efficiency rather than frustration, and the constraints of procurement law and associated practices which make such projects almost impossible to carry out successfully even if the required will and know-how were there.
The private sector is of course the other alternative. With law firms, the prevailing business model based on hourly billing offers no financial incentives for technological innovation, as most notably pointed out by Richard Susskind, and the attitudinal problems may not be all that different. Legal publishers are generally not much better, either. And overall, in large companies the organizational culture is usually geared towards an optimal execution of plans from above, making it too rigid to properly foster innovation, and for established small companies the required investment and the associated financial risk are too great.
So what is the solution? To all early-stage legal informatics researchers out there: Find yourselves a start-up! Either start one yourself (with a few other people with complementary skillsets) or find an existing one that is already trying to do something where your skills and knowledge should come in handy, maybe just on a consultancy basis. In the US, there are already over a hundred start-ups in the legal technology field. The number of start-ups doing intelligent legal technology (and European start-ups in the legal field in general) is already much smaller, so it should not be too difficult to gain a considerable advantage over the competition with the right idea and a solid implementation. I myself am fortunate enough to have found a way to leverage all the work I have done on MOSONG by co-founding Onomatics earlier this year.
This is not to say that just any idea, even one that is good enough to be the foundation for a doctoral thesis, will make for a successful business. This is indeed a common pitfall with the commercialization of academic research in general. Just starting with an existing idea, a prototype or even a complete system and then trying to find problems it (as such) could solve is a proven way to failure. If all you have is a hammer, all your problems start to look like nails. This is also very much the case with more sophisticated tools. A better approach is to first find a market need and then start working towards a marketable technological solution for it, of course using all one’s existing knowledge and technology whenever applicable, but without being constrained by them, when other methods work better.
Testing one’s theories by seeing whether they can actually be used to solve real-world problems is the best way forward towards broader relevance for one’s own work. Doing so typically involves considerable amounts of work that is neither scientifically interesting nor economically justifiable in an academic context, but which all the same is necessary to see if things work as they should. Because of this, such real-world integration is more feasible when done on a commercial basis. In this lies a considerable risk for the findings of this type of applied research to remain entirely confidential and proprietary as trade secrets, rather than becoming published at least to some degree, thus fuelling future research also in the broader research community and not just the individual company. To avoid this, active cooperation between the industry and academia should be encouraged.
 Anna Ronkainen is currently working as the Chief Scientist of Onomatics, Inc., a legal technology start-up of which she is a co-founder. Previously she has worked with language technology both commercially and academically for over fifteen years. She is a serial dropout with (somehow) a LL.M. from the University of Copenhagen, and she expects to defend her LL.D. thesis Fuzzy Systems and Legal Knowledge: Prolegomena to a Cognitive Theory of Law at the University of Helsinki during the 2013/14 academic year. She blogs at www.legalfuturology.com (with Anniina Huttunen) and blog.onomatics.com.
Anna Ronkainen is currently working as the Chief Scientist of Onomatics, Inc., a legal technology start-up of which she is a co-founder. Previously she has worked with language technology both commercially and academically for over fifteen years. She is a serial dropout with (somehow) a LL.M. from the University of Copenhagen, and she expects to defend her LL.D. thesis Fuzzy Systems and Legal Knowledge: Prolegomena to a Cognitive Theory of Law at the University of Helsinki during the 2013/14 academic year. She blogs at www.legalfuturology.com (with Anniina Huttunen) and blog.onomatics.com.
VoxPopuLII is edited by Judith Pratt. Editors-in-Chief are Stephanie Davidson and Christine Kirchberger, to whom queries should be directed.