



There has been much discussion on this blog about law-related information retrieval systems,
ontologies, and metadata. Today, I’d like to take you into another corner of legal informatics: rule-based legal information systems. I’ll tell you what they are, what their strengths and limitations are, and how they’re made. I’ll also explain why I’m optimistic about their potential to expand public access to law and to improve the way legal expertise is deployed and consumed.
First, what are they?
A rule-based expert system represents knowledge of a particular domain — such as medicine, finance, or law — in the form of “if-then” rules. Here’s an example of a rule:
the employee is entitled to standard FMLA leave IF
the employee is an eligible employee AND
the reason for the leave is enumerated in 29 U.S.C. § 2612
A rule consists of a bunch of variables (here, three Boolean statements) together with some logical operators (if, then, and, or, not, mathematical operators, etc.). Rules are chained together to form a rulebase, which is basically a database of rules. “Chained together” means that the rules connect to each other: a condition in one rule is the consequent or conclusion in another rule. For example, here’s a rule that links to our first rule:
the reason for the leave is enumerated in 29 U.S.C. § 2612 IF
the employee needs to care for a newborn child OR
the employee is becoming an adoptive or foster parent OR
the employee’s relative has a serious health condition OR
the employee cannot perform their job due to a serious health condition
Each of the conditions in this new rule can be defined by yet more rules. And other rules can sprout off of the main rule tree to form a complex web of inference. If we were to visualize such a network of rules, it might begin to look something like this:
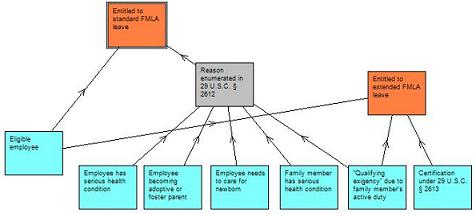
The rulebase inputs are shown in blue and the outputs – or “goals” – are highlighted in orange. The core function of the inference engine (or rule engine) is to figure out what conclusions can be drawn from the input facts. Also, given incomplete information, an inference engine will figure out what additional facts are needed in order to reach one of the goals.
Rule-based systems in context
From this extremely simple example we can start to get a sense of the strengths and limitations of rule-based representations of legal knowledge. Let’s start with the strengths. First, the law, to a significant degree, seems to consist of rules, and representing them in a constrained, logical language is fairly straightforward and natural. As a result, rule-based systems are transparent: the system code looks a lot like the text that’s being represented. This “isomorphism” means that you can trace the system logic back to the original source material, easily spot errors, and quickly adapt to changes in the law. Furthermore, rule-based systems can justify their determinations by explaining how they arrived at a particular conclusion and by providing audit trails. It’s also fairly easy for people to interact with rule-based systems, as they integrate well with interviews. In short, it’s relatively easy to put legal knowledge into rule-based systems, easy to maintain it, and easy to get it out.
But all this simplicity comes with a price: the sophistication of the knowledge that can be represented. For one thing, common sense knowledge does not lend itself to simple rule-based representations, as the decades-long Cyc project illustrates. A significant portion of my own rule-authoring effort is spent representing mundane concepts, like figuring whether a given date falls on a legal holiday or counting the number of weeks in which a given condition is true. Secondly, there’s the problem of how to model vague or “open-textured” concepts. For instance, if a liability determination turns upon whether a person’s conduct was “reasonable”, the uncertainty and fuzziness of that term can’t be modeled in a way analogous to human thinking. A third limitation facing rule-based systems is the “knowledge acquisition bottleneck.” This is the effort required to codify, test, and validate expert domain knowledge. Part of the challenge derives from the reasons I’ve already mentioned, and part results from the need to capture the knowledge of human subject matter experts who don’t always think in complete and precise “if-then” constructs. Another criticism often lodged at legal expert systems is that law is in essence not rule-based but is instead a fray of competing textual interpretations which cannot be accurately modeled.
My view is that, even given these limitations, there are still many problems that can be solved by rule-based systems. No one is asking them to solve all legal automation problems, or claiming that all legal knowledge can be represented in the form of rules. (Part of why little attention is paid to these systems today is that they were over-hyped during the artificial intelligence boom of the 1970s and 80s.) But there is a place for them, and that place is quite large even given the semantic confines that I just described. Rule-based systems are ideal for encoding legal principles found in statutes, regulations, and agency decisions — that is, law that’s explicit and knowable, but logically complicated. And there are millions of pages of such law, across thousands of jurisdictions around the world, just waiting to be embedded in rule-based systems.
Let me give you a few examples of what rule-based information systems can do, although chances are that you’ve already encountered one. Perhaps, like millions of American taxpayers, you used TurboTax tax preparation software to file your taxes this year. This and other tax preparation programs interview you about your income and finances, perform a multitude of behind-the-scenes calculations, and then fill out the relevant tax forms for you. I don’t actually know how this software was constructed, but if I were doing it I would absolutely take a rule-based approach. In fact, my team did use a rule engine when tasked to build a tax law advisory system for the IRS. That system, the Interactive Tax Assistant, answers seven common tax questions, is driven by about 1,300 rules, and contains around 200 question screens. Rule-based design can also produce systems like the Australian Visa Wizard, DirectLaw, and The Benefit Bank. Other rule-driven systems work behind the scenes at government agencies and corporations to process claims by making fast, consistent, and transparent decisions.
Available tools
In my view, the premier tool for engineering rule-based legal information systems is Oracle Policy Modeling (OPM, formerly known as Haley Office Rules, RuleBurst, and Softlaw). (Full disclosure: I used to work for Oracle.) OPM lets you write natural language rules that capture statutory text, calculations, date and time-based reasoning, and basic ontological relationships. It has decent debugging and rulebase visualization features (that’s how I created the rule network diagram above), and an excellent regression testing facility. OPM lets you deploy rulebases as Web interviews and integrate them into other computer systems. The major downside to OPM is its cost: I understand the list price to be in the ballpark of $100K per license.
You can also model legal rules using other business rule engines, such as ILOG, Blaze Advisor, JBoss Drools (free), and Jess (free). JBoss Drools has a promising feature that lets you create Domain Specific Languages by mapping natural language expressions to the underlying programming code. You could also use traditional logic programming / expert system languages like Prolog or CLIPS, which are extremely powerful but which do not allow for isomorphic representation of the law. OWL-centric ontology editors such as Protege are also beginning to support rule-based knowledge representation.
To address the lack of freely-available, practical legal modeling tools, I’ve been working on Jureeka.org, a project affiliated with Stanford’s CodeX Center for Computers and Law. Jureeka is an open, Web-based rule authoring platform that lets lawyers, law students, and other subject matter experts represent their knowledge as “if-then” rules. Jureeka then uses the rules to generate jurisdiction-specific interviews, which present the relevant topic in a digestible manner. Its strengths are that it’s completely Web-based, it makes navigation of the rules easy, and it lets rule authors work collaboratively to rapidly develop knowledge bases in a wiki-like fashion. The motivating vision is to provide a way for legal knowledge engineers to build topical rulebases, and then connect these modules together to form an information backbone that drives other IT systems and helps the general public get answers to their legal questions.
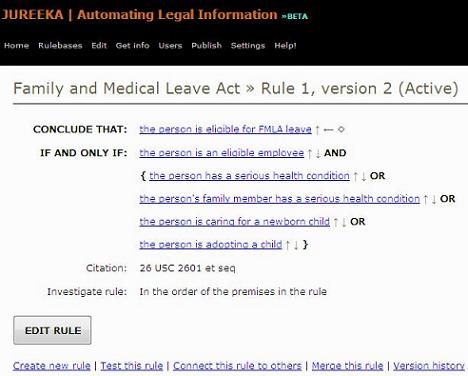
Jureeka is very much a work in progress, and I’ll be the first to admit that its main weakness is the oversimplicity of its rule syntax. (For example, I’m currently working on an ontology layer and a way to reason across multiple instances of an object or variable.) But this is the type of knowledge-generating project that I’d like to see a developer community coalesce around.
Future potential
Rule-based programming is not the be-all and end-all of legal informatics, but it does have significant untapped potential. Government agencies are beginning to adopt rule-based legal information systems as a way to better serve the public. I think there are also lucrative opportunities available for law firms to seize the first mover advantage by automating slices of the law of interest to consumers. Rule-based systems can help nonprofit organizations advance their missions by guiding constituents through labyrinthine legal processes. And these systems are of obvious benefit to corporations, which need to comply with a variety of regulations across numerous jurisdictions.
Rule-based systems can also benefit the legislative drafting process. For example, an early incarnation of the OPM software helped the Australian Taxation Office simplify that country’s tax code. In addition to this kind of legislative refactoring (which entails clarifying and reorganizing Rube Goldberg-like legal texts), legislatures could also promulgate law in an “inference-ready” machine readable form. That is, portions of the law could be written in a syntax that both humans and machines can read, making the law not only accessible but executable. I’m not merely referring to high-level metadata; I’m talking about code that is intended to be run in an inference engine and that can be deployed as is into society’s computing infrastructure. [See, e.g., Professor Monica Palmirani’s example of legal rules coded in the Legal Knowledge Interchange Format (LKIF) (at slides 48 through 50); please note that this is a 4.5M download.]
Some people have raised the objection that rule-based systems and their creators engage in the unauthorized practice of law by dispensing “legal advice.” I think this concern is overblown and founded upon a lack of understanding of how these systems work. Legal advice entails applying the law to the facts of a particular case or, conversely, interpreting facts in light of the applicable law. Rule-based systems don’t do that. Instead, they break up complicated legal provisions into atomic pieces and ask users to determine how each atom applies to them. Conceptually, it’s no different than reading a plain language description of legal rules and applying those rules to your own situation.
My goal in this post has been to introduce you to something that you may not have heard about and to convince you that it is a viable and worthwhile activity. Rule-based legal information systems have been around for a few decades, but we still have a long way to go until our rule-based legal modeling tools are as sophisticated as the Mathematica software is in the domain of mathematical computation. As we move in that direction, and as our legal knowledge engineering proficiency grows, we can advance toward the day when all people can take equal advantage of their legal rights. Knowing that they have them is the first step.
 Michael Poulshock is a consultant specializing in legal knowledge engineering and a Fellow at Stanford University’s CodeX Center for Computers and Law. He is the creator of Jureeka.org and the Jureeka legal research browser add-on for Firefox and Chrome. He was previously a human rights lawyer.
Michael Poulshock is a consultant specializing in legal knowledge engineering and a Fellow at Stanford University’s CodeX Center for Computers and Law. He is the creator of Jureeka.org and the Jureeka legal research browser add-on for Firefox and Chrome. He was previously a human rights lawyer.
VoxPopuLII is edited by Judith Pratt. Editor in chief is Robert Richards.