



In the fall of 2015, we wrote about a traffic spike that had occurred during one of the Republican primary debates. Traffic on the night of Sept. 16, 2015 peaked between 9 and 10pm, with a total of 47,025 page views during that interval. For that day, traffic totaled 204,905 sessions and 469,680 page views. At the time, the traffic level seemed like a big deal – our server had run out of resources to handle the traffic, and some of the people who had come to the site had to wait to find the content they were looking for – at that time, the 14th Amendment to the Constitution.
A year later, we found traffic topping those levels on most weekdays. But by that time, we barely noticed. Nic Ceynowa, who runs our systems, had, over the course of the prior year, systematically identified and addressed unnecessary performance-drains across the website. He replaced legacy redirection software with new, more efficient server redirects. He cached dynamic pages that we knew to be serving static data (because we know, for instance, that retired Supreme Court justices issue no new opinions). He throttled access to the most resource-intensive pages (web crawlers had to slow down a bit so that real people doing research could proceed as usual). As a result, he could allow more worker processes to field page requests and we could continue to focus on feature development rather than server load.
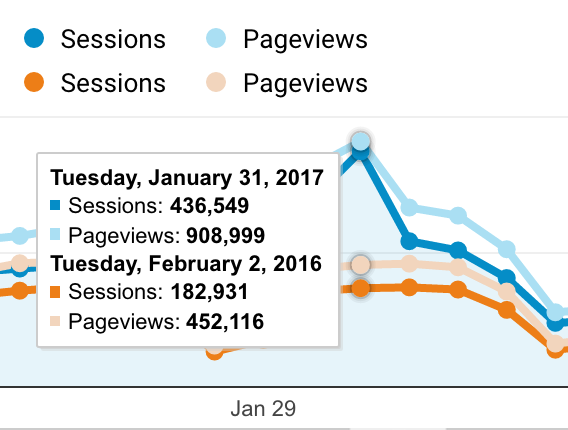
Then came the inauguration on January 20th. Presidential memoranda and executive orders inspired many, many members of the general public to read the law for themselves. Traffic hovered around 220,000 sessions per day for the first week. And then the President issued the executive order on immigration. By Sunday January 29th, we had 259,945 sessions – more than we expect on a busy weekday. On January 30th, traffic jumped to 347,393. And then on January 31st traffic peaked at 435,549 sessions – and over 900,000 page views.
The servers were still quiet. Throughout, we were able to continue running some fairly resource-hungry updating processes to keep the CFR current. We’ll admit to having devoted a certain amount of attention to checking in on the real-time analytics to see what people were looking at, but for the most part it was business as usual.
Now, the level of traffic we were talking about was still small compared to the traffic we once fielded when Bush v. Gore was handed down in 2000 (that day we had steady traffic of about 4000 requests per minute for 24 hours). And Nic is still planning to add clustering to our bag of tricks. But the painstaking work of the last year has given us a lot of breathing room – even when one of our fans gives us a really big internet hug. In the meantime, we’ve settled into the new normal and continue the slow, steady work of making the website go faster when people need it the most.