I just got back from the 2016 CALI conference at the Georgia State University College of Law in Atlanta, Georgia. This report of my time there is by no means an exhaustive or even chronological record of the conference. It's more of a highlight reel.

This was my second time attending and it still holds the title as my favorite conference. The food was great, the talks were excellent and there was a lot of time between sessions to have interesting conversations with many of the diverse and smart attendees who came from all over North America. Kudos to the organizers.
The conference officially started on Thursday, June 16th, when Indiana Jones, aka John Mayer, executive director of CALI, found the golden plaque of CALI after a harrowing traversal of the conference room, dodging obstacles. He gave a brief but warm welcome address and introduced the keynote speaker, Hugh McGuire, founder of PressBooks and LibriVox.org. With anecdotes from his biography, Mr Mcguire encouraged us to be proactive in solving big problems.
We had another keynote speaker on Friday, Michael Feldstein of Mindwires Consulting and co-producer of e-Literate TV.

He confessed to being something of a provocateur and succeeded in raising a few hackles when he asked, "Do law schools exist?" among other questions.
He then challenged us to do better at teaching students with different learning styles and skill-sets.
My two favorite presentations out of many excellent sessions were "The WeCite Project" by Pablo Arredondo from Casetext and "So you've digitized U.S. caselaw, now what?" by Adam Ziegler and Jack Cushman from the Harvard Library Innovation Lab.
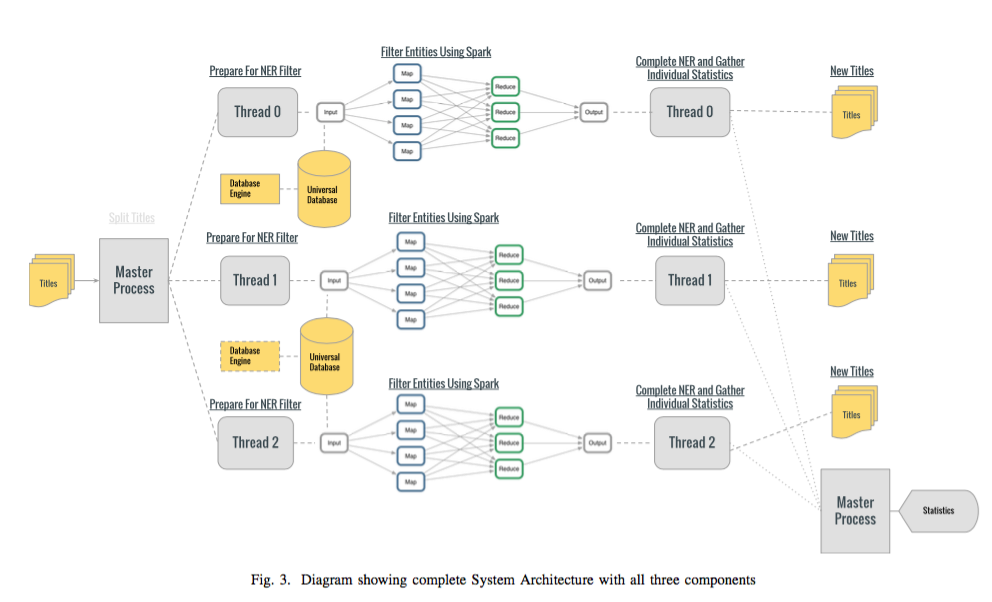
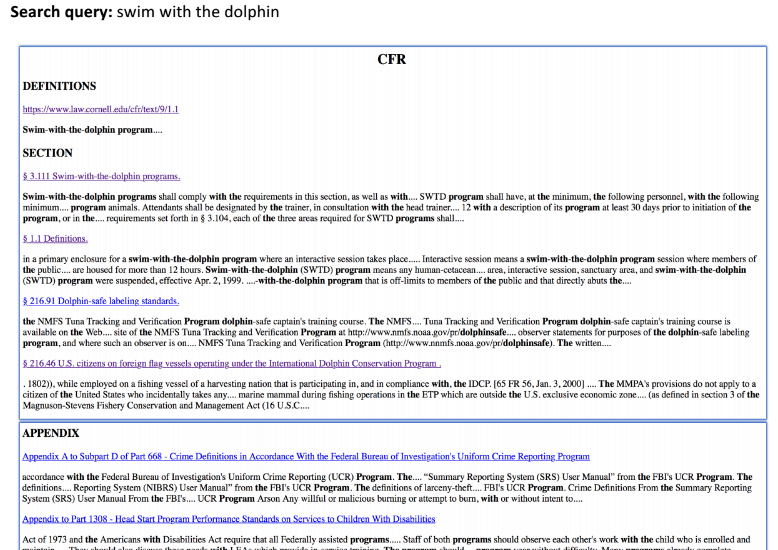
Pablo described teaching students to be their own legal shepherds by gamifying the creation and categorization of citator entries. The result of this effort is a database of every outgoing citation from the last 20 years of Supreme Court majority opinions and federal appellate courts, unambiguously labelled either as a positive, referencing, distinguishing, or negative citation. This data will be hosted by us (LII) and made freely available without restriction. In addition to the valuable data, he also shared how to engage students, librarians and research instructors as partners in the free law movement.
After a brief presentation of some of the ways they are beginning to use data from all the digitized case laws, Adam and Jack invited us to imagine what we could do with data. I can see possibilities for topic modeling, discovery of multi-faceted relationships between cases, and mapping of changes in contract conditions, etc. Many more features, tools and use cases were suggested by the other attendees. We welcome you to send us your personal wish list for features to make this information useful to you.
I also participated in a panel discussion on software management of large digital archives, moderated by Wilhelmina Randtke (Florida Academic Library Services Cooperative), along with Jack Cushman and Wei Fang (Assistant Dean for Information Technology and Head of Digital Services, Rutgers Law Library).
There was so much interest in the Oyez Project moving to the LII, that Craig's presentation on LII's use of web analytics, was replaced by a discussion hosted by Craig and Tim Stanley (Justia) on the transition. The rather lively discussion was made all the more entertaining by an impromptu costume change by Craig. The prevailing sentiment after the discussion was that the Oyez Project was in the best possible hands and 'safe'.
An unexpected bonus were the number of LII users who made it a point to complement the LII and express how useful they find our services. One particularly enthusiastic fan was DeAnna Swearington, Director of Operations at Quimbee.com (Learning tools for law students). I also met Wilson Tsu, CEO of LearnLeo and a Cornell alum, who had fond memories of when the LII first started. There were also several former law students who told me how invaluable the LII collections had been to them in school and continues to be in their current occupations.
All in all, a successful and enlightening conference. A big thank you to the organizers. They did an excellent job. I am already looking forward to next year!