



 The World Wide Web is a virtual cornucopia of legal information bearing on all manner of topics and in a spectrum of formats, much of it textual. However, to make use of this storehouse of textual information, it must be annotated and structured in such a way as to be meaningful to people and processable by computers. One of the visions of the Semantic Web has been to enrich information on the Web with annotation and structure. Yet, given that text is in a natural language (e.g., English, German, Japanese, etc.), which people can understand but machines cannot, some automated processing of the text itself is needed before further processing can be applied. In this article, we discuss one approach to legal information on the World Wide Web, the Semantic Web, and Natural Language Processing (NLP). Each of these are large, complex, and heterogeneous topics of research; in this short post, we can only hope to touch on a fragment and that heavily biased to our interests and knowledge. Other important approaches are mentioned at the end of the post. We give small working examples of legal textual input, the Semantic Web output, and how NLP can be used to process the input into the output.
The World Wide Web is a virtual cornucopia of legal information bearing on all manner of topics and in a spectrum of formats, much of it textual. However, to make use of this storehouse of textual information, it must be annotated and structured in such a way as to be meaningful to people and processable by computers. One of the visions of the Semantic Web has been to enrich information on the Web with annotation and structure. Yet, given that text is in a natural language (e.g., English, German, Japanese, etc.), which people can understand but machines cannot, some automated processing of the text itself is needed before further processing can be applied. In this article, we discuss one approach to legal information on the World Wide Web, the Semantic Web, and Natural Language Processing (NLP). Each of these are large, complex, and heterogeneous topics of research; in this short post, we can only hope to touch on a fragment and that heavily biased to our interests and knowledge. Other important approaches are mentioned at the end of the post. We give small working examples of legal textual input, the Semantic Web output, and how NLP can be used to process the input into the output.
Legal Information on the Web
For clients, legal professionals, and public administrators, the Web provides an unprecedented opportunity to search for, find, and reason with legal information such as case law, legislation, legal opinions, journal articles, and material relevant to discovery in a court procedure. With a search tool such as Google or indexed searches made available by Lexis-Nexis, Westlaw, or the World Legal Information Institute, the legal researcher can input key words into a search and get in return a (usually long) list of documents which contain, or are indexed by, those key words.
As useful as such searches are, they are also highly limited to the particular words or indexation provided, for the legal researcher must still manually examine the documents to find the substantive information. Moreover, current legal search mechanisms do not support more meaningful searches such as for properties or relationships, where, for example, a legal researcher searches for cases in which a company has the property of being in the role of plaintiff or where a lawyer is in the relationship of representing a client. Nor, by the same token, can searches be made with respect to more general (or more specific) concepts, such as “all cases in which a company has any role,” some particular fact pattern, legislation bearing on related topics, or decisions on topics related to a legal subject.
 The underlying problem is that legal textual information is expressed in natural language. What literate people read as meaningful words and sentences appear to a computer as just strings of ones and zeros. Only by imposing some structure on the binary code is it converted to textual characters as we know them. Yet, there is no similar widespread system for converting the characters into higher levels of structure which correlate to our understanding of meaning. While a search can be made for the string plaintiff, there are no (widely available) searches for a string that represents an individual who bears the role of plaintiff. To make language on the Web more meaningful and structured, additional content must be added to the source material, which is where the Semantic Web and Natural Language Processing come into play.
The underlying problem is that legal textual information is expressed in natural language. What literate people read as meaningful words and sentences appear to a computer as just strings of ones and zeros. Only by imposing some structure on the binary code is it converted to textual characters as we know them. Yet, there is no similar widespread system for converting the characters into higher levels of structure which correlate to our understanding of meaning. While a search can be made for the string plaintiff, there are no (widely available) searches for a string that represents an individual who bears the role of plaintiff. To make language on the Web more meaningful and structured, additional content must be added to the source material, which is where the Semantic Web and Natural Language Processing come into play.
Semantic Web
The Semantic Web is a complex of design principles and technologies which are intended to make information on the Web more meaningful and usable to people.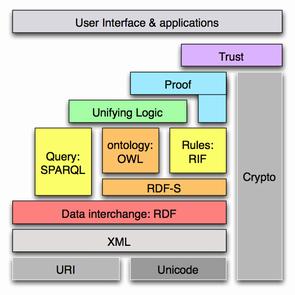 We focus on only a small portion of this structure, namely the syntactic XML (eXtensible Markup Language) level, where elements are annotated so as to indicate linguistically relevant information and structure. (Click here for more on these points.) While the XML level may be construed as a ‘lower’ level in the Semantic Web “stack” — i.e., the layers of interrelated technologies that make up the Semantic Web — the XML level is nonetheless crucial to providing information to higher levels where ontologies (and click here for more on this) and logic play a role. So as to be clear about the relation between the Semantic Web and NLP, we briefly review aspects of XML by example, and furnish motivations as we go.
We focus on only a small portion of this structure, namely the syntactic XML (eXtensible Markup Language) level, where elements are annotated so as to indicate linguistically relevant information and structure. (Click here for more on these points.) While the XML level may be construed as a ‘lower’ level in the Semantic Web “stack” — i.e., the layers of interrelated technologies that make up the Semantic Web — the XML level is nonetheless crucial to providing information to higher levels where ontologies (and click here for more on this) and logic play a role. So as to be clear about the relation between the Semantic Web and NLP, we briefly review aspects of XML by example, and furnish motivations as we go.
Suppose one looks up a case where Harris Hill is the plaintiff and Jane Smith is the attorney for Harris Hill. In a document related to this case, we would see text such as the following portions:
Harris Hill, plaintiff.
Jane Smith, attorney for the plaintiff.
While it is relatively straightforward to structure the binary string into characters, adding further information is more difficult. Consider what we know about this small fragment: Harris and Jane are (very likely) first names, Hill and Smith are last names, Harris Hill and Jane Smith are full names of people, plaintiff and attorney are roles in a legal case, Harris Hill has the role of plaintiff, attorney for is a relationship between two entities, and Jane Smith is in the attorney for relationship to Harris Hill. It would be useful to encode this information into a standardised machine-readable and processable form.
XML helps to encode the information by specifying requirements for tags that can be used to annotate the text. It is a highly expressive language, allowing one to define tags that suit one’s purposes so long as the specification requirements are met. One requirement is that each tag has a beginning and an ending; the material in between is the data that is being tagged. For example, suppose tags such as the following, where … indicates the data:
<legalcase>...</legalcase>,
<firstname>...</firstname>,
<lastname>...</lastname>,
<fullname>...</fullname>,
<plaintiff>...</plaintiff>,
<attorney>...</attorney>,
<legalrelationship>...</legalrelationship>
Another requirement is that the tags have a tree structure, where each pair of tags in the document is included in another pair of tags and there is no crossing over:
<fullname><firstname>...</firstname>,
<lastname>...</lastname></fullname>
is acceptable, but
<fullname><firstname>...<lastname>
</firstname> ...</lastname></fullname>
is unacceptable. Finally, XML tags can be organised into schemas to structure the tags.
With these points in mind, we could represent our fragment as:
<legalcase>
<legalrelationship>
<plaintiff>
<fullname><firstname>Harris</firstname>,
<lastname>Hill</lastname></fullname>
</plaintiff>,
<attorney>
<fullname><firstname>Jane</firstname>,
<lastname>Smith</lastname></fullname>
</attorney>
</legalrelationship
</legalcase>
We have added structured information — the tags — to the original text. While this is more difficult for us to read, it is very easy for a machine to read and process. In addition, the tagged text contains the content of the information, which can be presented in a range of alternative ways and formats using a transformation language such as XSLT (click here for more on this point) so that we have an easier-to-read format.
Why bother to include all this additional information in a legal text? Because these additions allow us to query the source text and submit the information to further processing such as inference. Given a query language, we could submit to the machine the query Who is the attorney in the case? and the answer would be Jane Smith. Given a rule language — such as RuleML or Semantic Web Rule Language (SWRL) — which has a rule such as If someone is an attorney for a client then that client has a privileged relationship with the attorney, it might follow from this rule that the attorney could not divulge the client’s secrets. Applying such a rule to our sample, we could infer that Jane Smith cannot divulge Harris Hill’s secrets.
 Though it may seem here like too much technology for such a small and obvious task, it is essential where we scale up our queries and inferences on large corpora of legal texts — hundreds of thousands if not millions of documents — which comprise vast storehouses of unstructured, yet meaningful data. Were all legal cases uniformly annotated, we could, in principle, find out every attorney for every plaintiff for every legal case. Where our tagging structure is very rich, our queries and inferences could also be very rich and detailed. Perhaps a more familiar way to view documents annotated with XML is as a database to which further processes can be applied over the Web.
Though it may seem here like too much technology for such a small and obvious task, it is essential where we scale up our queries and inferences on large corpora of legal texts — hundreds of thousands if not millions of documents — which comprise vast storehouses of unstructured, yet meaningful data. Were all legal cases uniformly annotated, we could, in principle, find out every attorney for every plaintiff for every legal case. Where our tagging structure is very rich, our queries and inferences could also be very rich and detailed. Perhaps a more familiar way to view documents annotated with XML is as a database to which further processes can be applied over the Web.
Natural Language Processing
As we have presented it, we have an input, the corpus of texts, and an output, texts annotated with XML tags. The objective is to support a range of processes such as querying and inference. However, getting from a corpus of textual information to annotated output is a demanding task, generically referred to as the knowledge acquisition bottleneck. Not only is the task demanding on resources (time, money, manpower); it is also highly knowledge intensive since whoever is doing the annotation must know what to look for, and it is important that all of the annotators annotate the text in the same way (inter-annotator agreement) to support the processes. Thus, automation is central.
Yet processing language to support such richly annotated documents confronts a spectrum of difficult issues. Among them, natural language supports (1) implicit or presupposed information, (2) multiple forms with the same meaning, (3) the same form with different contextually dependent meanings, and (4) dispersed meanings. (Similar points can be made for sentences or other linguistic elements.) Here are examples of these four issues:
(1) “When did you stop taking drugs?” (presupposes that the person being questioned took drugs at sometime in the past);
(2) Jane Smith, Jane R. Smith, Smith, Attorney Smith… (different ways to refer to the same person);
(3) The individual referred to by the name “Jane Smith” in one case decision may not be the individual referred to by the name “Jane Smith” in another case decision;
(4) Jane Smith represented Jones Inc. She works for Dewey, Cheetum, and Howe. To contact her, write to j.smith@dch.com .
When we search for information, a range of linguistic structures or relationships may be relevant to our query, such as:
- grammatical constructions (passive or active sentence forms, quotation, reference to other individuals, and so on),
- grammatical relations among terms (e.g., whether an individual is the agent or target of some action),
- ontological relations (e.g., classes and subclasses of experts, or the relationships among courts in the judicial hierarchy),
- relationships among elements (e.g., who works for what organization), or
- high-level patterns such as legal arguments (e.g., expert testimony) and fact patterns (e.g., culpable intent).
People grasp relationships between words and phrases, such that Bill exercises daily contrasts with the meaning of Bill is a couch potato, or that if it is true that Bill used a knife to kill Phil, then Bill killed Phil. Finally, meaning tends to be sparse; that is, there are a few words and patterns that occur very regularly, while most words or patterns occur relatively rarely in the corpus.
Natural language processing (NLP) takes on this highly complex and daunting problem as an engineering problem, decomposing large problems into smaller problems and subdomains until it gets to those which it can begin to address. Having found a solution to smaller problems, NLP can then address other problems or larger scope problems. Some of the subtopics in NLP are:
- Generation – converting information in a database into natural language.
- Understanding – converting natural language into a machine-readable form.
- Information Retrieval – gathering documents which contain key words or phrases. This is essentially what is done by Google.
- Text Summarization – summarizing (in a paragraph) the main meaning of a text or corpus.
- Question Answering – making queries and giving answers to them, in natural language, with respect to some corpus of texts.
- Information Extraction — identifying, annotating, and extracting information from documents for reuse, representation, or reasoning.
In this article, we are primarily (here) interested in information extraction.
NLP Approaches: Knowledge Light v. Knowledge Heavy
There are a range of techniques that one can apply to analyse the linguistic data obtained from legal texts; each of these techniques has strengths and weaknesses with respect to different problems. Statistical and machine-learning techniques are considered “knowledge light.” With statistical approaches, the processing presumes very little knowledge by the system (or analyst). Rather, algorithms are applied that compare and contrast large bodies of textual data, and identify regularities and similarities. Such algorithms encounter problems with sparse data or patterns that are widely dispersed across the text. (See Turney and Pantel (2010) for an overview of this area.) Machine learning approaches apply learning algorithms to annotated material to extend results to unannotated material, thus introducing more knowledge into the processing pipeline. However, the results are somewhat of a black box in that we cannot really know the rules that are learned and use them further.
With a “knowledge-heavy” approach, we know, in a sense, what we are looking for, and make this knowledge explicit in lists and rules for processing. Yet, this is labour- and knowledge-intensive. In the legal domain it is crucial to have humanly understandable explanations and justifications for the analysis of a text, which to our thinking warrants a knowledge-heavy approach.
One open source text-mining package, General Architecture for Text Engineering (GATE), consists of multiple components in a cascade or pipeline, each component automatically processing some aspect of the text, and then feeding into the next process. The underlying strategy in all the components is to find a pattern (from either a list or a previous process) which matches a rule, and then to apply the rule which annotates the text. Each component performs a particular process on the text, such as:
- Sentence segmentation – dividing text into sentences.
- Tokenisation – words identified by spaces between them.
- Part-of-speech tagging – noun, verb, adjective, etc., determined by look-up and relationships among words.
- Shallow syntactic parsing/chunking – dividing the text by noun phrase, verb phrase, subordinate clause, etc.
- Named entity recognition – the entities in the text such as organisations, people, and places.
- Dependency analysis – subordinate clauses, pronominal anaphora [i.e., identifying what a pronoun refers to], etc.
The system can also be used to annotate more specifically to elements of interest. In one study, we annotated legal cases from a case base (a corpus of cases) in order to identify a range of particular pieces of information that would be relevant to legal professionals such as:
- Case citation.
- Names of parties.
- Roles of parties, meaning plaintiff or defendant.
- Type of court.
- Names of judges.
- Names of attorneys.
- Roles of attorneys, meaning the side they represent.
- Final decision.
- Cases cited.
- Nature of the case, meaning using keywords to classify the case in terms of subject (e.g., criminal assault, intellectual property, etc.)
Applying our lists and rules to a corpus of legal cases, a sample output is as follows, where the coloured highlights are annotated as per the key on the right; the colours are a visualisation of the sorts of tags discussed above (to see a larger version of the image, right click on the image, then click on “View Image” or a similar phrase; when finished viewing the image, use the browser’s back button to return to the text):

The approach is very flexible and appears in similar systems. (See, for example, de Maat and Winkels, Automatic Classification of Sentences in Dutch Laws (2008).) While it is labour intensive to develop and maintain such list and rule systems, with a collaborative, Web-based approach, it may be feasible to construct rich systems to annotate large domains.
Conclusion
In this post, we have given a very brief overview of how the Semantic Web and Natural Language Processing (NLP) apply to legal textual information to support annotation which then enables querying and inference. Of course, this is but one take on a much larger domain. In our view, it holds great promise in making legal information more transparent and available to more legal professionals. Aside from GATE, some other resources on text analytics and NLP are textbooks and lecture notes (see, e.g., Wilcock), as well as workshops (such as SPLeT and LOAIT). While applications of Natural Language Processing to legal materials are largely lab studies, the use of NLP in conjunction with Semantic Web technology to annotate legal texts is a fast-developing, results-oriented area which targets meaningful applications for legal professionals. It is well worth watching.
 Dr. Adam Zachary Wyner is a Research Fellow at the University of Leeds, Institute of Communication Studies, Centre for Digital Citizenship. He currently works on the EU-funded project IMPACT: Integrated Method for Policy Making Using Argument Modelling and Computer Assisted Text Analysis. Dr. Wyner has a Ph.D. in Linguistics (Cornell, 1994) and a Ph.D. in Computer Science (King’s College London, 2008). His computer science Ph.D. dissertation is entitled Violations and Fulfillments in the Formal Representation of Contracts. He has published in the syntax and semantics of adverbs, deontic logic, legal ontologies, and argumentation theory with special reference to law. He is workshop co-chair of SPLeT 2010: Workshop on Semantic Processing of Legal Texts, to be held 23 May 2010 in Malta. He writes about his research at his blog, Language, Logic, Law, Software.
Dr. Adam Zachary Wyner is a Research Fellow at the University of Leeds, Institute of Communication Studies, Centre for Digital Citizenship. He currently works on the EU-funded project IMPACT: Integrated Method for Policy Making Using Argument Modelling and Computer Assisted Text Analysis. Dr. Wyner has a Ph.D. in Linguistics (Cornell, 1994) and a Ph.D. in Computer Science (King’s College London, 2008). His computer science Ph.D. dissertation is entitled Violations and Fulfillments in the Formal Representation of Contracts. He has published in the syntax and semantics of adverbs, deontic logic, legal ontologies, and argumentation theory with special reference to law. He is workshop co-chair of SPLeT 2010: Workshop on Semantic Processing of Legal Texts, to be held 23 May 2010 in Malta. He writes about his research at his blog, Language, Logic, Law, Software.
VoxPopuLII is edited by Judith Pratt. Editor in chief is Robert Richards.