


LII Team Wins Googliest Project Award

Imagine you’re opening a new business that uses water in the production cycle. If you want to know what federal regulations apply to you, you might do a Google search that leads to the Code of Federal Regulations. But that’s where it gets complicated, because the law contains hundreds of regulations involving water that are difficult to narrow down. (The CFR alone contains 13898 references to water.) For example, water may be defined one way when referring to a drinkable liquid and another when defined as an emission from a manufacturing facility. If the regulation says your water must maintain a certain level of purity, to which water are they referring? Definitions are the building blocks of the law, and yet pouring through them to find what applies to you is frustrating to an average business owner. Computer automation might help, but how can a computer understand exactly what kind of water you’re looking for? We at the Legal Information Institute think this is pretty important challenge, and apparently Google does too.
In March, a team of three Masters of Engineering Students led by LII semantic web researcher and developer Mohammad AL Asswad took home honors at BOOM (Bits on Our Minds), the Cornell Department of Computing and Information Science’s annual student technology showcase. Faced with stiff competition from underwater robots and other student innovations, students Deepthi Rajagopalan, Neha Kulkarni, and Siyu Zhan worked with Mohammad on a project designed to help LII users find definitions within the US Code of Federal Regulations. This year’s “Googliest Project Award” included a glass trophy and a $250 cash prize made possible by, you guessed it, Google. The LII team was one of only six award winners selected from over 40 competing projects.
Working collaboratively with Cornell Law School students Alice Chavaillard and Rodica Turtoi, the team developed software that uses natural language processing and machine learning techniques to identify sections of federal law that define important terms. In this collaborative project, the Cornell Law students served as domain area experts and helped to produce the data needed to train the computers to classify a paragraph of text as a definition or non-definition. The engineering team then wrote software that determines the scope of the definition (where the definition applies), parses out the defined terms, and finds the boundaries of definitions that are long and complex. Once defined, the definition may be linked to other parts of relevant regulations. So when you find the term water in your particular regulation, you can click the term to be taken to the specific definition of water that applies to you, whether the definition resides in that regulation or in another section of the law.
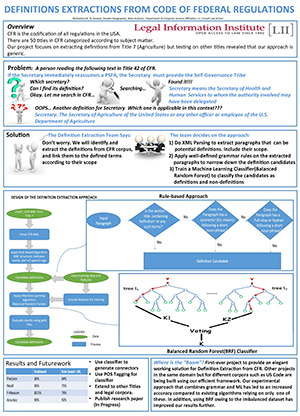 While still in the early stages, this type of semantic infrastructure is the next phase of Internet development, in which human understanding can be assisted by a computer’s ability to understand the context in which certain words or phrases are used. You can see the details of the team’s research in this poster, which was part of their prize winning presentation. Expect more on this project in the months ahead.
While still in the early stages, this type of semantic infrastructure is the next phase of Internet development, in which human understanding can be assisted by a computer’s ability to understand the context in which certain words or phrases are used. You can see the details of the team’s research in this poster, which was part of their prize winning presentation. Expect more on this project in the months ahead.