As Technology Changes, LII’s Mission Stays the Same
Friends,
We wanted to give you a “state of the LII” update to correspond with the State of the Union address; but, as usual, we didn’t want to wait for the government:
First, a big THANK YOU to everyone who made a gift to LII during our campaign. Because Cornell processes different forms of donations very differently, we don’t have final totals just yet. But even as those last reports trickle in, we already know that we remain on pace to not only meet our financial obligations to our staff, our students, our vendors, etc. but also to pursue the travel, training, and collaboration opportunities that are so important to helping us find the best uses for our expertise in this shifting landscape.
You may have noticed that each of our six fundraising emails from late in 2023 made at least a passing reference to the impacts of generative AI on what we do. (The fifth even used the phrase “existential crises abound” while the sixth called artificial intelligence technologies “an existential game-changer.”) The rise of generative AI in 2023 represents arguably the single biggest disruption to the way the public accesses legal information online since the advent of the worldwide web itself three decades ago.
AI is certain to change the way people look for, find, and use information online – to say nothing of how it’s produced! That, in turn, is already causing us to analyze everything about how 2024 and beyond will be different from everything that has come before: everything from how we might best use student labor to how we’ll get the money we need to run our operation to how our collections might (or might not) be used not only by AI tools but by folks who need to verify the accuracy of their outputs. And the list goes on and on.
In reviewing 2023, we were struck not only by the pace of change, but also by just how much time and effort we spent preparing for what’s to come while not having clarity about what that future looks like. As tools emerge that promise to improve the efficiency of all of our work, we are able to abandon a certain amount of patience for inefficiencies of the past. In the process, we’ve been able to streamline our operations and save (donor) money by migrating to systems covered by large University-negotiated enterprise contracts; retire outdated tools; and take advantage of emerging services to flatten the learning curve for all of the students who show up to work with us for a summer, a semester, or a year.
These improvements enabled us to focus on seeking out new ways to understand how the LII website is used–whether by people or by machines. Again this year, we worked with undergraduates, graduate engineering students, law students, and recent graduates (more than 80 in all) to extend, update, and enhance our original content offerings. The result totals more than 700 created and revised Wex entries, such updates to the overviews on taking of hostages, and artificial intelligence. The Women & Justice collection added a bilingual summary of the Guatemala Law Against Femicide and Other Forms of Violence Against Women, and numerous provisions of the Trafficking in Persons Act of Trinidad and Tobago. And the LII Supreme Court Bulletin published previews for all of the cases argued before the Court, including heavily-read previews this fall for Alexander v. South Carolina NAACP, Lindke v. Freed, and United States v. Rahimi.
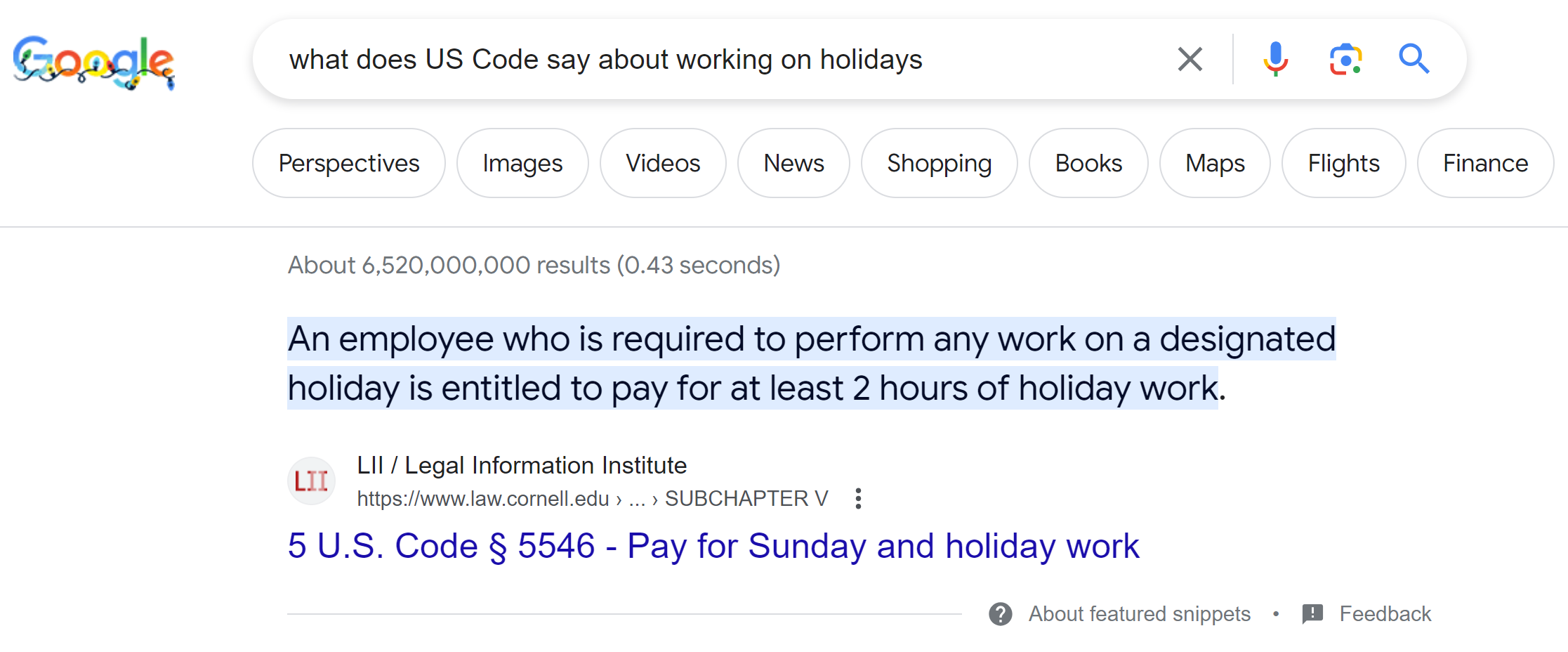
We also had our hands full keeping current the many collections of primary content for which the public has come to rely on us. This year, we weathered a number of changes in government data sources, using the improvements to refine our focus on the features we are uniquely well-situated to create and publish in a way that will be discoverable and usable. We updated our processing for U.S. Supreme Court decisions and the U.S. Constitution Annotated and have another round of updating ahead of us. The latest version of the U.S. Constitution Annotated includes discussions of Students for Fair Admissions, Inc. v. President and Fellows of Harvard College, Moore v. Harper, and 303 Creative v. Elenis among many more. And the next round of updates should make it vastly easier to maintain print citations, setting the stage for better interoperability among all of our resources on constitutional law.
In addition to publishing, we pushed ahead on applied research-driven features. A recent Cornell JD made use of new retrieval-augmented generation (AI) techniques to prototype data preparation for extracting 50-state survey information about blue sky laws. Our software is now extracting close to a million definitions from state regulations, surfacing variations among states on many topics, including floodplains. (If you’re curious how that came up, as it happens, FEMA is redrawing the Ithaca, NY flood map for the first time in more than 40 years, and “100-year flood” topped our alphabetical defined terms list – curiosity got the better of us). Finally, an M.Eng. project produced a mapping of a popular topical ontology designed for legal practice to the state regulations. So in addition to keeping current on publishing our content, we hope that as the millions of readers show up to the website, we will have more tools than ever to help them learn the law, do their jobs, and generally live their lives.
Despite the work and the chaos and all that goes with the havoc that AI threatens to wreak in our field and so many others, we will continue to develop, test, refine, implement, and share innovative techniques for making legal information more findable and comprehensible for the public. We hope you’ll come along for the ride.